
Monotone Documentation
Monotone is a distributed version control tool. It can help automate many tedious and error-prone tasks in group software development.
Please be aware that monotone is a slightly unorthodox version control tool, and many of its concepts are slightly similar — but significantly different — from concepts with similar names in other version control tools.
Complete table of contents
This chapter should familiarize you with the concepts, terminology, and behavior described in the remainder of the user manual. Please take a moment to read it, as later sections will assume familiarity with these terms.
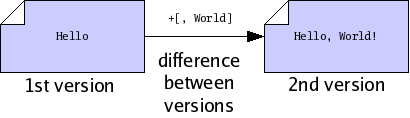
Suppose you wish to modify a file file.txt on your computer. You begin with one version of the file, load it into an editor, make some changes, and save the file again. Doing so produces a new version of the file. We will say that the older version of the file was a parent, and the new version is a child, and that you have performed an edit between the parent and the child. We may draw the relationship between parent and child using a graph, where the arrow in the graph indicates the direction of the edit, from parent to child.
We may want to identify the parent and the child precisely, for sake of reference. To do so, we will compute a cryptographic hash function, called sha1, of each version. The details of this function are beyond the scope of this document; in summary, the sha1 function takes a version of a file and produces a short string of 20 bytes, which we will use to uniquely identify the version1. Now our graph does not refer to some “abstract” parent and child, but rather to the exact edit we performed between a specific parent and a specific child.

When dealing with versions of files, we will dispense with writing out “file names”, and identify versions purely by their sha1 value, which we will also refer to as their file ID. Using IDs alone will often help us accommodate the fact that people often wish to call files by different names. So now our graph of parent and child is just a relationship between two versions, only identified by ID.

Version control systems, such as monotone, are principally concerned with the storage and management of multiple versions of some files. One way to store multiple versions of a file is, literally, to save a separate complete copy of the file, every time you make a change. When necessary, monotone will save complete copies of your files in their, compressed with the zlib compression format.

Often we find that successive versions of a file are very similar to one another, so storing multiple complete copies is a waste of space. In these cases, rather than store complete copies of each version of a file, we store a compact description of only the changes which are made between versions. Such a description of changes is called a delta.
Storing deltas between files is, practically speaking, as good as storing complete versions of files. It lets you undo changes from a new version, by applying the delta backwards, and lets your friends change their old version of the file into the new version, by applying the delta forwards. Deltas are usually smaller than full files, so when possible monotone stores deltas, using a modified xdelta format. The details of this format are beyond the scope of this document.
After you have made many different files, you may wish to capture a “snapshot” of the versions of all the files in a particular collection. Since files are typically collected into trees in a file system, we say that you want to capture a version of your tree. Doing so will permit you to undo changes to multiple files at once, or send your friend a set of changes to many files at once.
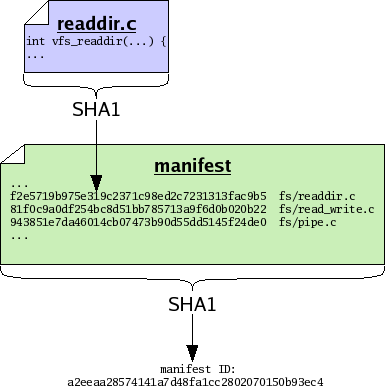
To make a snapshot of a tree, we begin by writing a special file called a manifest. In fact, monotone will write this file for us, but we could write it ourselves too. It is just a plain text file. Each line of a manifest file contains two columns. In the first column we write the ID of a file in your tree, and in the second column we write the path to the file, from the root of our tree to the filename.

Now we note that a manifest is itself a file. Therefore a manifest can serve as input to the sha1 function, and thus every manifest has an ID of its own. By calculating the sha1 value of a manifest, we capture the state of our tree in a single manifest ID. In other words, the ID of the manifest essentially captures all the IDs and file names of every file in our tree, combined. So we may treat manifests and their IDs as snapshots of a tree of files, though lacking the actual contents of the files themselves.
As with versions of files, we may decide to store manifests in their entirety, or else we may store only a compact description of changes which occur between different versions of manifests. As with files, when possible monotone stores compact descriptions of changes between manifests; when necessary it stores complete versions of manifests.
Suppose you sit down to edit some files. Before you start working, you may record a manifest of the files, for reference sake. When you finish working, you may record another manifest. These “before and after” snapshots of the tree of files you worked on can serve as historical records of the set of changes, or changeset, that you made. In order to capture a “complete” view of history – both the changes made and the state of your file tree on either side of those changes – monotone builds a special composite file called a revision each time you make changes. Like manifests, revisions are ordinary text files which can be passed through the sha1 function and thus assigned a revision ID.

The content of a revision makes reference to file IDs, in describing a changeset, and manifest IDs, in describing tree states “before and after” the changeset. Crucially, revisions also make reference to other revision IDs. This fact – that revisions include the IDs of other revisions – causes the set of revisions to join together into a historical chain of events, somewhat like a “linked list”. Each revision in the chain has a unique ID, which includes by reference all the revisions preceeding it. Even if you undo a changeset, and return to a previously-visited manifest ID during the course of your edits, each revision will incorporate the ID of its predecessor, thus forming a new unique ID for each point in history.

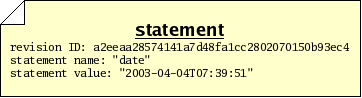
Often, you will wish to make a statement about a revision, such as stating the reason that you made some changes, or stating the time at which you made the changes, or stating that the revision passes a test suite. Statements such as these can be thought of, generally, as a bundle of information with three parts:
For example, if you want to say that a particular revision was composed on April 4, 2003, you might make a statement like this:
In an ideal world, these are all the parts of a statement we would need in order to go about our work. In the real world, however, there are sometimes malicious people who would make false or misleading statements; so we need a way to verify that a particular person made a particular statement about a revision. We therefore will add two more pieces of information to our bundle:
When these 2 items accompany a statement, we call the total bundle of 5 items a certificate, or cert. A cert makes a statement in a secure fashion. The security of the signature in a cert is derived from the rsa cryptography system, the details of which are beyond the scope of this document.

Monotone uses certs extensively. Any “extra” information which needs to be stored, transmitted or retrieved — above and beyond files, manifests, and revisions — is kept in the form of certs. This includes change logs, time and date records, branch membership, authorship, test results, and more. When monotone makes a decision about storing, transmitting, or extracting files, manifests, or revisions, the decision is often based on certs it has seen, and the trustworthiness you assign to those certs.
The rsa cryptography system — and therefore monotone itself — requires that you exchange special “public” numbers with your friends, before they will trust certificates signed by you. These numbers are called public keys. Giving someone your public key does not give them the power to impersonate you, only to verify signatures made by you. Exchanging public keys should be done over a trusted medium, in person, or via a trusted third party. Advanced secure key exchange techniques are beyond the scope of this document.
Most of monotone's certs refer to revision IDs. Some certs may refer to file IDs or manifest IDs, depending on context. This capability may also be removed in the future, at which point certs will only refer to revisions.
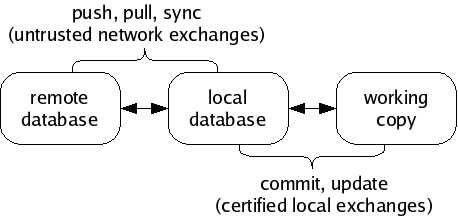
Monotone moves information in and out of three different types of storage:
All information passes through your local database, en route to some other destination. For example, when changes are made in a working copy, you may save those changes to your database, and later you may synchronize your database with someone else's. Monotone will not move information directly between a working copy and a remote database, or between working copies. Your local database is always the “switching point” for communication.
A working copy is a tree of files in your file system, arranged according to the list of file paths and IDs in a particular manifest. A special directory called MT exists in the root of any working copy. Monotone keeps some special files in the MT directory, in order to track changes you make to your working copy.
Aside from the special MT directory, a working copy is just a normal tree of files. You can directly edit the files in a working copy using a plain text editor or other program; monotone will automatically notice when you make any changes. If you wish to add files, remove files, or move files within your working copy, you must tell monotone explicitly what you are doing, as these actions cannot be deduced.
If you do not yet have a working copy, you can check out a working copy from a database, or construct one from scratch and add it into a database. As you work, you will occasionally commit changes you have made in a working copy to a database, and update a working copy to receive changes that have arrived in a database. Committing and updating take place purely between a database and a working copy; the network is not involved.

A database is a single, regular file. You can copy or back it up using standard methods. Typically you keep a database in your home directory. Databases are portable between different machine types. If a database grows too big, you may choose to remove information from it. You can have multiple databases and divide your work between them, or keep everything in a single database if you prefer. You can dump portions of your database out as text, and read them back into other databases, or send them to your friends.
A database contains many files, manifests, revisions, and certificates, some of which are not immediately of interest, some of which may be unwanted or even false. It is a collection of information received from network servers, working copies, and other databases. You can inspect and modify your databases without affecting your working copies, and vice-versa.
Monotone knows how to exchange information in your database with other remote databases, using an interactive protocol called netsync. It supports three modes of exchange: pushing, pulling, and synchronizing. A pull operation copies data from a remote database to your local database. A push operation copies data from your local database to a remote database. A sync operation copies data both directions. In each case, only the data missing from the destination is copied. The netsync protocol calculates the data to send “on the fly” by exchanging partial hash values of each database.

In general, work flow with monotone involves 3 distinct stages:
The last stage of workflow is worth clarifying: monotone does not blindly apply all changes it receives from a remote database to your working copy. Doing so would be very dangerous, because remote databases are not always trustworthy systems. Rather, monotone evaluates the certificates it has received along with the changes, and decides which particular changes are safe and desirable to apply to your working copy.
You can always adjust the criteria monotone uses to judge the trustworthiness and desirability of changes in your database. But keep in mind that it always uses some criteria; receiving changes from a remote server is a different activity than applying changes to a working copy. Sometimes you may receive changes which monotone judges to be untrusted or bad; such changes may stay in your database but will not be applied to your working copy.
Remote databases, in other words, are just untrusted “buckets” of data, which you can trade with promiscuously. There is no trust implied in communication.
So far we have been talking about revisions as though each logically follows exactly one revision before it, in a simple sequence of revisions.

This is a rosy picture, but sometimes it does not work out this way. Sometimes when you make new revisions, other people are simultaneously making new revisions as well, and their revisions might be derived from the same parent as yours, or contain different changesets. Without loss of generality, we will assume simultaneous edits only happen two-at-a-time; in fact many more edits may happen at once but our reasoning will be the same.
We call this situation of simultaneous edits a fork, and will refer to the two children of a fork as the left child and right child. In a large collection of revisions with many people editing files, especially on many different computers spread all around the world, forks are a common occurrence.
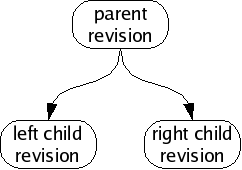
If we analyze the changes in each child revision, we will often find that the changeset between the parent and the left child are unrelated to the changeset between the parent and the right child. When this happens, we can usually merge the fork, producing a common grandchild revision which contains both changesets.

Sometimes, people intentionally produce forks which are not supposed to be merged; perhaps they have agreed to work independently for a time, or wish to change their files in ways which are not logically compatible with each other. When someone produces a fork which is supposed to last for a while (or perhaps permanently) we say that the fork has produced a new branch. Branches tell monotone which revisions you would like to merge, and which you would like to keep separate.
You can see all the available branches using monotone list branches.
Branches are indicated with certs. The cert name branch is
reserved for use by monotone, for the purpose of identifying the
revisions which are members of a branch. A branch cert has a
symbolic “branch name” as its value. When we refer to “a branch”,
we mean all revisions with a common branch name in their branch
certs.
For example, suppose you are working on a program called “wobbler”.
You might develop many revisions of wobbler and then decide to split
your revisions into a “stable branch” and an “unstable branch”, to
help organize your work. In this case, you might call the new branches
“wobbler-stable” and “wobbler-unstable”. From then on, all
revisions in the stable branch would get a cert with name branch
and value wobbler-stable; all revisions in the unstable branch
would get a cert with name branch and value
wobbler-unstable. When a wobbler-stable revision forks,
the children of the fork will be merged. When a
wobbler-unstable revision forks, the children of the fork will
be merged. However, the wobbler-stable and
wobbler-unstable branches will not be merged together, despite
having a common ancestor.

For each branch, the set of revisions with no children is called the heads of the branch. Monotone can automatically locate, and attempt to merge, the heads of a branch. If it fails to automatically merge the heads, it may ask you for assistance or else fail cleanly, leaving the branch alone.
For example, if a fork's left child has a child of its own (a “left grandchild”), monotone will merge the fork's right child with the left grandchild, since those revisions are the heads of the branch. It will not merge the left child with the right child, because the left child is not a member of the heads.

When there is only one revision in the heads of a branch, we say that the heads are merged, or more generally that the branch is merged, since the heads is the logical set of candidates for any merging activity. If there are two or more revisions in the heads of a branch, and you ask to merge the branch, monotone will merge them two-at-a-time until there is only one.
The branch names used in the above section are fine for an example, but they would be bad to use in a real project. The reason is, monotone branch names must be globally unique, over all branches in the world. Otherwise, bad things can happen. Fortunately, we have a handy source of globally unique names — the DNS system.
When naming a branch, always prepend the reversed name of a host that
you control or are otherwise authorized to use. For example, monotone
development happens on the branch net.venge.monotone, because
venge.net belongs to monotone's primary author. The idea is that
this way, you can coordinate with other people using a host to make sure
there are no conflicts — in the example, monotone's primary author can
be certain that no-one else using venge.net will start up a
different program named monotone. If you work for Yoyodyne,
Inc. (owners of yoyodyne.com), then all your branch names should look
like com.yoyodyne.something.
What the something part looks like is up to you, but
usually the first part is the project name (the monotone in
net.venge.monotone), and then possibly more stuff after that to
describe a particular branch. For example, monotone's win32 support
was initially developed on the branch net.venge.monotone.win32.
(For more information, see Naming Conventions.)
This chapter illustrates the basic uses of monotone by means of an example, fictional software project. Before we walk through the tutorial, there are two minor issues to address: standard options and revision selectors.
Before operating monotone, two important command-line options should be explained.
Monotone will cache the settings for these options in your working copy, so ordinarily once you have checked out a project, you will not need to specify them again. We will therefore only mention these arguments in the first example.
Many commands require you to supply 40-character sha1 values as arguments, which identify revisions. These “revision IDs” are tedious to type, so monotone permits you to supply “revision selectors” rather than complete revision IDs. Selectors are a more “human friendly” way of specifying revisions by combining certificate values into unique identifiers. This “selector” mechanism can be used anywhere a revision ID would normally be used. For details on selector syntax, see Selectors.
We are now ready to explore our fictional project.
Our fictional project involves 3 programmers cooperating to write firmware for a robot, the JuiceBot 7, which dispenses fruit juice. The programmers are named Jim, Abe and Beth.
In our example the programmers work privately on laptops, and are usually disconnected from the network. They share no storage system. Thus when each programmer enters a command, it affects only his or her own computer, unless otherwise stated.
In the following, our fictional project team will work through several version control tasks. Some tasks must be done by each member of our example team; other tasks involve only one member.
The first step Jim, Abe and Beth each need to perform is to create a
new database. This is done with the monotone db init command,
providing a --db option to specify the location of the new
database. Each programmer creates their own database, which will
reside in their home directory and store all the revisions, files and
manifests they work on. Monotone requires this step as an explicit
command, to prevent spurious creation of databases when an invalid
--db option is given.
In real life, most people prefer to keep one database for each project
they work on. If we followed that convention here in the tutorial,
though, then all the databases would be called juicebot.db, and
that would make things more confusing to read. So instead, we'll have
them each name their database after themselves.
Thus Jim issues the command:
$ monotone db init --db=~/jim.db
Abe issues the command:
$ monotone db init --db=~/abe.db
And Beth issues the command:
$ monotone db init --db=~/beth.db
Now Jim, Abe and Beth must each generate an rsa key pair for themselves. This step requires choosing a key identifier. Typical key identifiers are similar to email addresses, possibly modified with some prefix or suffix to distinguish multiple keys held by the same owner. Our example programmers will use their email addresses at the fictional “juicebot.co.jp” domain name. When we ask for a key to be generated, monotone will ask us for a passphrase. This phrase is used to encrypt the key when storing it on disk, as a security measure.
Jim does the following:
$ monotone --db=~/jim.db genkey [email protected]
enter passphrase for key ID [[email protected]] : <Jim enters his passphrase>
monotone: generating key-pair '[email protected]'
monotone: storing key-pair '[email protected]' in database
Abe does something similar:
$ monotone --db=~/abe.db genkey [email protected]
enter passphrase for key ID [[email protected]] : <Abe enters his passphrase>
monotone: generating key-pair '[email protected]'
monotone: storing key-pair '[email protected]' in database
as does Beth:
$ monotone --db=~/beth.db genkey [email protected]
enter passphrase for key ID [[email protected]] : <Beth enters her passphrase>
monotone: generating key-pair '[email protected]'
monotone: storing key-pair '[email protected]' in database
Each programmer has now generated a key pair and placed it in their local database. Each can list the keys in their database, to ensure the correct key was generated. For example, Jim might see this:
$ monotone --db=~/jim.db list keys
[public keys]
9e9e9ef1d515ad58bfaa5cf282b4a872d8fda00c [email protected]
[private keys]
771ace046c27770a99e5fddfa99c9247260b5401 [email protected]
The hexadecimal string printed out before each key name is a fingerprint of the key, and can be used to verify that the key you have stored under a given name is the one you intended to store. Monotone will never permit one database to store two keys with the same name or the same fingerprint.
This output shows one private and one public key stored under the name
[email protected], so it indicates that Jim's key-pair has
been successfully generated and stored. On subsequent commands, Jim
will need to re-enter our passphrase in order to perform
security-sensitive tasks. To simplify matters, Jim decides to store
his security passphrase in his .monotonerc file, by writing a
hook function which returns the passphrase, so that he does not
need to repeatedly be prompted for it:
$ cat >>~/.monotonerc
function get_passphrase(keypair_id)
return "jimsekret"
end
^D
Note that we are appending the new hook to the (possibly existing) file.
We do this to avoid loosing other changes by mistake; therefore, be sure
to check that no other get_passphrase function appears in the
configuration file.
Abe and Beth do the same, with their secret passphrases.
Jim, Abe and Beth all wish to work with one another, and trust one another. For monotone to accept this situation, the team members will need to exchange the public parts of their rsa key with each other.
First, Jim exports his public key:
$ monotone --db=~/jim.db pubkey [email protected] >~/jim.pubkey
His public key is just a plain block of ASCII text:
$ cat ~/jim.pubkey
[pubkey [email protected]]
MIGdMA0GCSqGSIb3DQEBAQUAA4GLADCBhwKBgQCbaVff9SF78FiB/1nUdmjbU/TtPyQqe/fW
CDg7hSg1yY/hWgClXE9FI0bHtjPMIx1kBOig09AkCT7tBXM9z6iGWxTBhSR7D/qsJQGPorOD
DO7xovIHthMbZZ9FnvyB/BCyiibdWgGT0Gtq94OKdvCRNuT59e5v9L4pBkvajb+IzQIBEQ==
[end]
Abe also exports his public key:
$ monotone --db=~/abe.db pubkey [email protected] >~/abe.pubkey
As does Beth:
$ monotone --db=~/beth.db pubkey [email protected] >~/beth.pubkey
Then all three team members exchange keys. The keys are not secret, but the team members must be relatively certain that they are communicating with the person they intend to trust, when exchanging keys, and not some malicious person pretending to be a team member. Key exchange may involve sending keys over an encrypted medium, or meeting in person to exchange physical copies, or any number of techniques. All that matters, ultimately, is for each team member to receive the keys of the others.
So eventually, after key exchange, Jim has Beth's and Abe's public key files in his home directory, along with his own. He tells monotone to read the associated key packets into his database:
$ monotone --db=~/jim.db read <~/abe.pubkey
monotone: read 1 packet
$ monotone --db=~/jim.db read <~/beth.pubkey
monotone: read 1 packet
Beth and Abe similarly tell monotone to read read the two new public keys they received into their respective databases.
Before they can begin work on the project, Jim needs to create a
working copy — a directory whose contents monotone will keep track
of. Often, one works on projects that someone else has started, and
creates working copies with the checkout command, which you'll
learn about later. Jim is starting a new project, though, so he does
something a little bit different. He uses the monotone setup
command to create a new working copy.
This command creates the named directory (if it doesn't already exist),
and creates the MT directory within it. The MT directory
is how monotone recognizes that a directory is a working copy, and
monotone stores some bookkeeping files within it. For instance, command
line values for the --db, --branch or --key
options to the setup command will be cached in a file called
MT/options, so you don't have to keep passing them to monotone
all the time.
Jim creates his working copy:
/home/jim$ monotone setup juice
/home/jim$ cd juice
/home/jim/juice$
Notice that Jim has changed his current directory to his newly created working copy. For the rest of this example we will assume that everyone issues all further monotone commands from their working copy directories.
Next Jim decides to add some files to the project. He writes up a file containing the prototypes for the JuiceBot 7:
$ mkdir include
$ cat >include/jb.h
/* Standard JuiceBot hw interface */
#define FLOW_JUICE 0x1
#define POLL_JUICE 0x2
int spoutctl(int port, int cmd, void *x);
/* JuiceBot 7 API */
#define APPLE_SPOUT 0x7e
#define BANANA_SPOUT 0x7f
void dispense_apple_juice ();
void dispense_banana_juice ();
^D
Then adds a couple skeleton source files which he wants Abe and Beth to fill in:
$ mkdir src
$ cat >src/apple.c
#include "jb.h"
void
dispense_apple_juice()
{
/* Fill this in please, Abe. */
}
^D
$ cat >src/banana.c
#include "jb.h"
void
dispense_banana_juice()
{
/* Fill this in please, Beth. */
}
^D
Now Jim tells monotone to add these files to its record of his working copy. He specifies one filename and one directory; monotone recursively scans the directory and adds all its files.
$ monotone --db=~/jim.db add include/jb.h src
monotone: adding include/jb.h to working copy add set
monotone: adding src/apple.c to working copy add set
monotone: adding src/banana.c to working copy add set
This command produces a record of Jim's intentions in a special file called MT/work, stored in the working copy. The file is plain text:
$ cat MT/work
add_file "include/jb.h"
add_file "src/apple.c"
add_file "src/banana.c"
Jim then gets up from his machine to get a coffee. When he returns he has forgotten what he was doing. He asks monotone:
$ monotone --db=jim.db status
new_manifest [2098eddbe833046174de28172a813150a6cbda7b]
old_revision []
old_manifest []
add_file "include/jb.h"
add_file "src/apple.c"
add_file "src/banana.c"
patch "include/jb.h"
from []
to [3b12b2d0b31439bd50976633db1895cff8b19da0]
patch "src/apple.c"
from []
to [2650ffc660dd00a08b659b883b65a060cac7e560]
patch "src/banana.c"
from []
to [e8f147e5b4d5667f3228b7bba1c5c1e639f5db9f]
The output of this command tells Jim that his edits, so far, constitute only the addition of some files. In the output we can see one pecularity of monotone's changeset format. The pecularity is that when monotone records a “new file”, it actually records two separate events: the addition of an empty file to the working copy, and a patch of that file from empty to its intended contents.
Jim wants to see the actual details of the files he added, however, so he runs a command which prints out the status and a GNU “unified diff” of the patches involved in the changeset:
$ monotone --db=jim.db diff
#
# add_file "include/jb.h"
#
# add_file "src/apple.c"
#
# add_file "src/banana.c"
#
# patch "include/jb.h"
# from []
# to [3b12b2d0b31439bd50976633db1895cff8b19da0]
#
# patch "src/apple.c"
# from []
# to [2650ffc660dd00a08b659b883b65a060cac7e560]
#
# patch "src/banana.c"
# from []
# to [e8f147e5b4d5667f3228b7bba1c5c1e639f5db9f]
#
--- include/jb.h
+++ include/jb.h
@ -0,0 +1,13 @
+/* Standard JuiceBot hw interface */
+
+#define FLOW_JUICE 0x1
+#define POLL_JUICE 0x2
+#define SET_INTR 0x3
+int spoutctl(int port, int cmd, void *x);
+
+/* JuiceBot 7 API */
+
+#define APPLE_SPOUT 0x7e
+#define BANANA_SPOUT 0x7f
+void dispense_apple_juice ();
+void dispense_banana_juice ();
--- src/apple.c
+++ src/apple.c
@ -0,0 +1,7 @
+#include "jb.h"
+
+void
+dispense_apple_juice()
+{
+ /* Fill this in please, Abe. */
+}
--- src/banana.c
+++ src/banana.c
@ -0,0 +1,7 @
+#include "jb.h"
+
+void
+dispense_banana_juice()
+{
+ /* Fill this in please, Beth. */
+}
Satisfied with the work he's done, Jim wants to save his changes. He
chooses jp.co.juicebot.jb7 as a branch name. (See Naming Conventions for more information about appropriate branch names.) He
then commits his working copy, which causes monotone to process the
MT/work file and record the file contents, manifest, and revision
into the database.
$ monotone --db=jim.db --branch=jp.co.juicebot.jb7 commit --message='initial checkin of project'
monotone: beginning commit
monotone: manifest 2098eddbe833046174de28172a813150a6cbda7b
monotone: revision 2e24d49a48adf9acf3a1b6391a080008cbef9c21
monotone: branch jp.co.juicebot.jb7
monotone: committed revision 2e24d49a48adf9acf3a1b6391a080008cbef9c21
Monotone did a number of things when committing the new revision. First, we can see from the output that monotone generated a manifest of the tree Jim committed. The manifest is stored inside the database, but Jim can print it out if he wants to see the exact state of all the files referenced by the revision he committed:
$ monotone cat manifest
3b12b2d0b31439bd50976633db1895cff8b19da0 include/jb.h
2650ffc660dd00a08b659b883b65a060cac7e560 src/apple.c
e8f147e5b4d5667f3228b7bba1c5c1e639f5db9f src/banana.c
The column on the left contains cryptographic hashes of the files listed in the column on the right. Such a hash is also called the “file ID” of the file. The file ID identifies the state of each file stored in Jim's tree. The manifest is just a plain text file, identical to the output from the popular sha1sum unix command.
When monotone committed Jim's revision, it also erased the MT/work file, and wrote a new file called MT/revision, which contains the working copy's new base revision ID. Jim can use this revision ID in the future, as an argument to the checkout command, if he wishes to return to this revision:
$ cat MT/revision
2e24d49a48adf9acf3a1b6391a080008cbef9c21
Finally, monotone also generated a number of certificates, attached to the new revision. These certs store metadata about the commit. Jim can ask monotone for a list of certs on this revision.
$ monotone ls certs 2e24d49a48adf9acf3a1b6391a080008cbef9c21
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : branch
Value : jp.co.juicebot.jb7
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : date
Value : 2004-10-26T02:53:08
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : author
Value : [email protected]
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : changelog
Value : initial checkin of project
The output of this command has a block for each cert found. Each block
has 4 significant pieces of information. The first indicates the
signer of the cert, in this case [email protected]. The
second indicates whether this cert is “ok”, meaning whether the
rsa signature provided is correct for the cert data. The third is
the cert name, and the fourth is the cert value. This list shows us
that monotone has confirmed that, according to
[email protected], the revision
2e24d49a48adf9acf3a1b6391a080008cbef9c21 is a member of the
branch jp.co.juicebot.jb7, written by
[email protected], with the given date and changelog.
It is important to keep in mind that revisions are not “in” or “out” of a branch in any global sense, nor are any of these cert values true or false in any global sense. Each cert indicates that some person – in this case Jim – would like to associate a revision with some value; it is up to you to decide if you want to accept that association.
Jim can now check the status of his branch using the “heads” command, which lists all the head revisions in the branch:
$ monotone heads
branch 'jp.co.juicebot.jb7' is currently merged:
2e24d49a48adf9acf3a1b6391a080008cbef9c21 [email protected] 2004-10-26T02:53:08
The output of this command tells us that there is only one current
“head” revision in the branch jp.co.juicebot.jb7, and it is
the revision Jim just committed. A head revision is one without any
descendents. Since Jim has not committed any changes to this revision
yet, it has no descendents.
Jim now decides he will make his base revision available to his employees. To do this first adds a small amount of extra information to his .monotonerc file, permitting Abe and Beth to access his database:
$ cat >>~/.monotonerc
function get_netsync_read_permitted (collection, identity)
if (identity == "[email protected]") then return true end
if (identity == "[email protected]") then return true end
return false
end
function get_netsync_write_permitted (collection, identity)
if (identity == "[email protected]") then return true end
if (identity == "[email protected]") then return true end
return false
end
function get_netsync_anonymous_read_permitted (collection)
return false
end
^D
He then makes sure that his TCP port 5253 is open to incoming connections, adjusting his firewall settings as necessary, and runs the monotone serve command:
$ monotone --db=jim.db serve jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
This command sets up a single listener loop on the host
jim-laptop.juicebot.co.jp, serving the
jp.co.juicebot.jb7 collection. This collection will naturally
include the jp.co.juicebot.jb7 branch, and any sub-branches.
Now Abe decides he wishes to fetch Jim's code. To do this he issues
the monotone sync command:
monotone --db=abe.db sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
monotone: rebuilding merkle trees for collection jp.co.juicebot.jb7
monotone: connecting to jim-laptop.juicebot.co.jp
monotone: [bytes in: 3200] [bytes out: 673]
monotone: successful exchange with jim-laptop.juicebot.co.jp
Abe now has, in his database, a copy of everything Jim put in the branch. Therefore Abe can disconnect from the expensive network connection he's on and work locally for a while. When Abe wants to send work back to Jim, or get new work Jim has added, all he needs to do is run the sync command again and work will flow both ways, bringing each party up to date with the work of the other.
At this point Jim is operating as a sort of “central server” for the company. If Jim wants to, he can leave his server running forever, or even put his server on a dedicated computer with better network connectivity. But if Jim is ever unable to play this role of “central server”, perhaps due to a network failure, either Beth or Abe can run the serve command and provide access for the other to sync with. In fact, each employee can run a server if they like, concurrently, to help minimize the risk of service disruption from hardware failures. Changes will flow between servers automatically as clients access them and trade with one another.
In practice, most people like to use at least one central server that is always running; this way, everyone always knows where to go to get the latest changes, and people can push their changes out without first calling their friends and making sure that they have their servers running. To support this style of working, monotone remembers the first server you use, and makes that the default for future operations.
Abe decides to do some work on his part of the code. He has a copy of
Jim's database contents, but cannot edit any of that data yet. He
begins his editing by checking out the head of the
jp.co.juicebot.jb7 branch into a working copy, so he can edit
it:
$ monotone --db=abe.db --branch=jp.co.juicebot.jb7 checkout .
Monotone unpacks the set of files in the head revision's manifest directly into Abe's current directory. (If he had specified something other than . at the end, monotone would have created that directory and unpacked the files into it.) Abe then opens up one of the files, src/apple.c, and edits it:
$ vi src/apple.c
<Abe writes some apple-juice dispensing code>
The file src/apple.c has now been changed. Abe gets up to answer a phone call, and when he returns to his work he has forgotten what he changed. He can ask monotone for details:
$ monotone diff
#
# patch "src/apple.c"
# from [2650ffc660dd00a08b659b883b65a060cac7e560]
# to [e2c418703c863eabe70f9bde988765406f885fd0]
#
--- src/apple.c
+++ src/apple.c
@ -1,7 +1,10 @
#include "jb.h"
void
dispense_apple_juice()
{
- /* Fill this in please, Abe. */
+ spoutctl(APPLE_SPOUT, FLOW_JUICE, 1);
+ while (spoutctl(APPLE_SPOUT, POLL_JUICE, 1) == 0)
+ usleep (1000);
+ spoutctl(APPLE_SPOUT, FLOW_JUICE, 0);
}
Satisfied with his day's work, Abe decides to commit.
$ monotone commit
monotone: beginning commit
monotone: manifest b33cb337dccf21d6673f462d677a6010b60699d1
monotone: revision 70decb4b31a8227a629c0e364495286c5c75f979
monotone: branch jp.co.juicebot.jb7
Abe neglected to provide a --message option specifying the change log on the command line and the file MT/log is empty because he did not document his changes there. Monotone therefore invokes an external “log message editor” — typically an editor like vi — with an explanation of the changes being committed and the opportunity to enter a log message.
polling implementation of src/apple.c
MT:
MT: ----------------------------------------------------------------------
MT: Enter Log. Lines beginning with `MT:' are removed automatically
MT:
MT: new_manifest [b33cb337dccf21d6673f462d677a6010b60699d1]
MT:
MT: old_revision [2e24d49a48adf9acf3a1b6391a080008cbef9c21]
MT: old_manifest [2098eddbe833046174de28172a813150a6cbda7b]
MT:
MT: patch "src/apple.c"
MT: from [2650ffc660dd00a08b659b883b65a060cac7e560]
MT: to [e2c418703c863eabe70f9bde988765406f885fd0]
MT:
MT: ----------------------------------------------------------------------
MT:
Abe enters a single line above the explanatory message, saying “polling implementation of src/apple.c”. He then saves the file and quits the editor. Monotone deletes all the lines beginning with “MT:” and leaves only Abe's short message. Returning to the shell, Abe's commit completes:
monotone: committed revision 70decb4b31a8227a629c0e364495286c5c75f979
Abe then sends his new revision back to Jim:
$ monotone sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
monotone: rebuilding merkle trees for collection jp.co.juicebot.jb7
monotone: including branch jp.co.juicebot.jb7
monotone: [keys: 2] [rcerts: 8]
monotone: connecting to jim-laptop.juicebot.co.jp
monotone: [bytes in: 630] [bytes out: 2844]
monotone: successful exchange with jim-laptop.juicebot.co.jp
Beth does a similar sequence. First she syncs her database with Jim's:
monotone --db=beth.db sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
monotone: rebuilding merkle trees for collection jp.co.juicebot.jb7
monotone: connecting to jim-laptop.juicebot.co.jp
monotone: [bytes in: 3200] [bytes out: 673]
monotone: successful exchange with jim-laptop.juicebot.co.jp
She checks out a copy of the tree from her database:
$ monotone --db=beth.db --branch=jp.co.juicebot.jb7 checkout .
She edits the file src/banana.c:
$ vi src/banana.c
<Beth writes some banana-juice dispensing code>
and logs her changes in MT/log right away so she does not forget what she has done like Abe.
$ vi MT/log
* src/banana.c: Added polling implementation
and logs her changes in MT/log right away so she does not forget what she has done:
$ vi MT/log
* src/banana.c: Added polling implementation
Later, she commits her work. Monotone again invokes an external editor for her to edit her log message, but this time it fills in the messages she's written so far, and she simply checks them over one last time before finishing her commit:
$ monotone commit
monotone: beginning commit
monotone: manifest eaebc3c558d9e30db6616ef543595a5a64cc6d5f
monotone: revision 80ef9c9d251d39074d37e72abf4897e0bbae1cfb
monotone: branch jp.co.juicebot.jb7
monotone: committed revision 80ef9c9d251d39074d37e72abf4897e0bbae1cfb
And she syncs with Jim again:
$ monotone sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
monotone: rebuilding merkle trees for collection jp.co.juicebot.jb7
monotone: including branch jp.co.juicebot.jb7
monotone: [keys: 3] [rcerts: 12]
monotone: connecting to jim-laptop.juicebot.co.jp
monotone: [bytes in: 630] [bytes out: 2844]
monotone: successful exchange with jim-laptop.juicebot.co.jp
Careful readers will note that, in the previous section, the JuiceBot company's work was perfectly serialized:
The result of this ordering is that Jim's work entirely preceeded Abe's work, which entirely preceeded Beth's work. Moreover, each worker was fully informed of the “up-stream” worker's actions, and produced purely derivative, “down-stream” work:
This is a simple, but sadly unrealistic, ordering of events. In real companies or work groups, people often work in parallel, diverging from commonly known revisions and merging their work together, sometime after each unit of work is complete.
Monotone supports this diverge/merge style of operation naturally; any time two revisions diverge from a common parent revision, we say that the revision graph has a fork in it. Forks can happen at any time, and require no coordination between workers. In fact any interleaving of the previous events would work equally well; with one exception: if forks were produced, someone would eventually have to run the merge command, and possibly resolve any conflicts in the fork.
To illustrate this, we return to our workers Beth and Abe. Suppose Jim sends out an email saying that the current polling juice dispensers use too much CPU time, and must be rewritten to use the JuiceBot's interrupt system. Beth wakes up first and begins working immediately, basing her work off the revision 80ef9... which is currently in her working copy:
$ vi src/banana.c
<Beth changes her banana-juice dispenser to use interrupts>
Beth finishes and examines her changes:
$ monotone diff
#
# patch "src/banana.c"
# from [7381d6b3adfddaf16dc0fdb05e0f2d1873e3132a]
# to [5e6622cf5c8805bcbd50921ce7db86dad40f2ec6]
#
--- src/banana.c
+++ src/banana.c
@ -1,10 +1,15 @
#include "jb.h"
+static void
+shut_off_banana()
+{
+ spoutctl(BANANA_SPOUT, SET_INTR, 0);
+ spoutctl(BANANA_SPOUT, FLOW_JUICE, 0);
+}
+
void
-dispense_banana_juice()
+dispense_banana_juice()
{
+ spoutctl(BANANA_SPOUT, SET_INTR, &shut_off_banana);
spoutctl(BANANA_SPOUT, FLOW_JUICE, 1);
- while (spoutctl(BANANA_SPOUT, POLL_JUICE, 1) == 0)
- usleep (1000);
- spoutctl(BANANA_SPOUT, FLOW_JUICE, 0);
}
She commits her work:
$ monotone commit --message='interrupt implementation of src/banana.c'
monotone: beginning commit
monotone: manifest de81e46acb24b2950effb18572d5166f83af3881
monotone: revision 8b41b5399a564494993063287a737d26ede3dee4
monotone: branch jp.co.juicebot.jb7
monotone: committed revision 8b41b5399a564494993063287a737d26ede3dee4
And she syncs with Jim:
$ monotone sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
Unfortunately, before Beth managed to sync with Jim, Abe had woken up and implemented a similar interrupt-based apple juice dispenser, but his working copy is 70dec..., which is still “upstream” of Beth's.
$ vi apple.c
<Abe changes his apple-juice dispenser to use interrupts>
Thus when Abe commits, he unknowingly creates a fork:
$ monotone commit --message='interrupt implementation of src/apple.c'
Abe does not see the fork yet; Abe has not actually seen any of Beth's work yet, because he has not synchronized with Jim. Since he has new work to contribute, however, he now syncs:
$ monotone sync jim-laptop.juicebot.co.jp jp.co.juicebot.jb7
Now Jim and Abe will be aware of the fork. Jim sees it when he sits down at his desk and asks monotone for the current set of heads of the branch:
$ monotone heads
monotone: branch 'jp.co.juicebot.jb7' is currently unmerged:
39969614e5a14316c7ffefc588771f491c709152 [email protected] 2004-10-26T02:53:16
8b41b5399a564494993063287a737d26ede3dee4 [email protected] 2004-10-26T02:53:15
Clearly there are two heads to the branch: it contains an un-merged fork. Beth will not yet know about the fork, but in this case it doesn't matter: anyone can merge the fork, and since there are no conflicts Jim does so himself:
$ monotone merge
monotone: merging with revision 1 / 2
monotone: [source] 39969614e5a14316c7ffefc588771f491c709152
monotone: [source] 8b41b5399a564494993063287a737d26ede3dee4
monotone: common ancestor 70decb4b31a8227a629c0e364495286c5c75f979 found
monotone: trying 3-way merge
monotone: [merged] da499b9d9465a0e003a4c6b2909102ef98bf4e6d
monotone: your working copies have not been updated
The output of this command shows Jim that two heads were found, combined via a 3-way merge with their ancestor, and saved to a new revision. This happened automatically, because the changes between the common ancestor and heads did not conflict. If there had been a conflict, monotone would have invoked an external merging tool to help resolve it.
After merging, the branch has a single head again, and Jim updates his working copy.
$ monotone update
monotone: selected update target da499b9d9465a0e003a4c6b2909102ef98bf4e6d
monotone: updating src/apple.c to f088e24beb43ab1468d7243e36ce214a559bdc96
monotone: updating src/banana.c to 5e6622cf5c8805bcbd50921ce7db86dad40f2ec6
monotone: updated to base revision da499b9d9465a0e003a4c6b2909102ef98bf4e6d
The update command selected an update target — in this case the newly merged head — and performed an in-memory merge between Jim's working copy and the chosen target. The result was then written to Jim's working copy. If Jim's working copy had any uncommitted changes in it, they would have been merged with the update in exactly the same manner as the merge of multiple committed heads.
Monotone makes very little distinction between a “pre-commit” merge (an update) and a “post-commit” merge. Both sorts of merge use the exact same algorithm. The major difference concerns the recoverability of the pre-merge state: if you commit your work first, and merge after committing, the merge can fail (due to difficulty in a manual merge step) and your committed state is still safe. It is therefore recommended that you commit your work first, before merging.
This chapter covers slightly less common aspects of using monotone. Some users of monotone will find these helpful, though possibly not all. We assume that you have read through the taxonomy and tutorial, and possibly spent some time playing with the program to familiarize yourself with its operation.
Revisions can be specified on the monotone command line, precisely, by entering the entire 40-character hexadecimal sha1 code. This can be cumbersome, so monotone also allows a more general syntax called “selectors” which is less precise but more “human friendly”. Any command which expects a precise revision ID can also accept a selector in its place; in fact a revision ID is just a special type of selector which is very precise.
Some selector examples are helpful in clarifying the idea:
a432a432
[email protected]/2004-04[email protected] in April 2004.
'[email protected]/2 weeks ago'[email protected] 2 weeks ago.
graydon/net.venge.monotone.win32/yesterdaynet.venge.monotone.win32 branch, written by
graydon, yesterday.
A moment's examination reveals that these specifications are “fuzzy” and indeed may return multiple values, or may be ambiguous. When ambiguity arises, monotone will inform you that more detail is required, and list various possibilities. The precise specification of selectors follows.
A selector is a combination of a selector type, which is a single
ASCII character, followed by a : character and a selector
value. The value is matched against identifiers or certs, depending on
its type, in an attempt to match a single revision. Selectors are
matched as prefixes. The current set of selection types are:
a. For example, a:graydon matches
author certs where the cert value begins with graydon.
b. For example, b:net.venge matches
branch certs where the cert value begins with net.venge.
d. For example, d:2004-04 matches
date certs where the cert value begins with 2004-04.
i. For example, i:0f3a matches
revision IDs which begin with 0f3a.
t. For example, t:monotone-0.11
matches tag certs where the cert value begins with
monotone-0.11.
Further selector types may be added in the future.
Selectors may be combined with the / character. The combination
acts as database intersection (or logical and). For example,
the selector a:graydon/d:2004-04 can be used to select a
revision which has an author cert beginning with graydon
as well as a date cert beginning with 2004-04.
Before selectors are passed to the database, they are expanded using a
lua hook: expand_selector. The default definition of this hook
attempts to guess a number of common forms for selection, allowing you
to omit selector types in many cases. For example, the hook guesses
that the typeless selector [email protected] is an author
selector, due to its syntactic form, so modifies it to read
a:[email protected]. This hook will generally assign a selector
type to values which “look like” partial hex strings, email
addresses, branch names, or date specifications. For the complete
source code of the hook, see Hook Reference.
If, after expansion, a selector still has no type, it is matched as a
special “unknown” selector type, which will match either a tag, an
author, or a branch. This costs slightly more database access, but
often permits simple selection using an author's login name and a
date. For example, the selector
graydon/net.venge.monotone.win32/yesterday would pass through
the selector graydon as an unknown selector; so long as there
are no branches or tags beginning with the string graydon this
is just as effective as specifying a:graydon.
Several monotone commands accept optional pathname... arguments in order to establish a “restriction”. Restrictions are used to limit the files and directories these commands examine for changes when comparing the working copy to the revision it is based on. Restricting a command to a specified set of files or directories simply ignores changes to files or directories not included by the restriction.
The following commands all support restrictions using optional pathname... arguments:
Including either the old or new name of a renamed file or directory will cause both names to be included in a restriction. If in doubt, the status command can be used to “test” a set of pathnames to ensure that the expected files are included or excluded by a restriction.
One variant of the diff command takes two --revision options and does not operate on a working copy, but instead compares two arbitrary database revisions. In this form the diff command does not currently support a restriction or optional pathname... arguments. This may be changed in the future.
The update command does not allow for updates to a restricted set of files, which may be slightly different than other version control systems. Partial updates don't really make sense in monotone, as they would leave the working copy based on a revision that doesn't exist in the database, starting an entirely new line of development.
The restrictions facility also allows commands to operate from within a subdirectory of the working copy. By default, the entire working copy is always examined for changes. However, specifying an explicit "." pathname to a command will restrict it to the current subdirectory. Note that this is quite different from other version control systems and may seem somewhat surprising.
The expectation is that requiring a single "." to restrict to the current subdirectory should be simple to use. While the alternative, defaulting to restricting to the current subdirectory, would require a somewhat complicated ../../.. sequence to remove the restriction and operate on the whole tree.
This default was chosen because monotone versions whole project trees and generally expects to commit all changes in the working copy as a single atomic unit. Other version control systems often version individual files or directories and may not support atomic commits at all.
When working from within a subdirectory of the working copy all paths specified to monotone commands must be relative to the current subdirectory.
Monotone only stores a single MT directory at the root of a working copy. Because of this, a search is done to find the MT directory in case a command is executed from within a subdirectory of a working copy. Before a command is executed, the search for a working copy directory is done by traversing parent directories until an MT directory is found or the filesystem root is reached. Upon finding an MT directory, the MT/options file is read for default options. The --root option may be used to stop the search early, before reaching the root of the physical filesystem.
Many monotone commands don't require a working copy and will simply proceed with no default options if no MT directory is found. However, some monotone commands do require a working copy and will fail if no MT directory can be found.
The checkout and setup commands create a new working copy and initialize a new MT/options file based on their current option settings.
People often want to write programs that call monotone — for example, to create a graphical interface to monotone's functionality, or to automate some task. For most programs, if you want to do this sort of thing, you just call the command line interface, and do some sort of parsing of the output. Monotone's output, however, is designed for humans: it's localized, it tries to prompt the user with helpful information depending on their request, if it detects that something unusual is happening it may give different output in an attempt to make this clear to the user, and so on. As a result, it is not particularly suitable for programs to parse.
Rather than trying to design output to work for both humans and
computers, and serving neither audience well, we elected to create a
separate interface to make programmatically extracting information from
monotone easier. The command line interface has a command
automate; this command has subcommands that print various sorts
of information on standard output, in simple, consistent, and easily
parseable form.
For details of this interface, see Automation.
Monotone was constructed to serve both as a version control tool and as a quality assurance tool. The quality assurance features permit users to ignore, or “filter out”, versions which do not meet their criteria for quality. This section describes the way monotone represents and reasons about quality information.
Monotone often views the collection of revisions as a directed graph,
in which revisions are the nodes and changes between revisions are the
edges. We call this the revision graph. The revision graph has a
number of important subgraphs, many of which overlap. For example,
each branch is a subgraph of the revision graph, containing only the
nodes carrying a particular branch cert.
Many of monotone's operations involve searching the revision graph for
the ancestors or descendants of a particular revision, or extracting
the “heads” of a subgraph, which is the subgraph's set of nodes with
no descendants. For example, when you run the update command,
monotone searches the subgraph consisting of descendants of the base
revision of the current working copy, trying to locate a unique head to
update the base revision to.
Monotone's quality assurance mechanisms are mostly based on restricting the subgraph each command operates on. There are two methods used to restrict the subgraph:
branch certificates, you
can require that specific code reviewers have approved of each edge in
the subgraph you focus on.
testresult certificates, you
can require that the endpoints of an update operation have a
certificate asserting that the revision in question passed a certain
test, or testsuite.
The evaluation of trust is done on a cert-by-cert basis by calling a
set of lua hooks: get_revision_cert_trust,
get_manifest_cert_trust and get_file_cert_trust. These
hooks are only called when a cert has at least one good signature from
a known key, and are passed all the keys which have signed the
cert, as well as the cert's id, name and value. The hook can then
evaluate the set of signers, as a group, and decide whether to grant
or deny trust to the assertion made by the cert.
The evaluation of testresults is controlled by the
accept_testresult_change hook. This hook is called when
selecting update candidates, and is passed a pair of tables describing
the testresult certs present on the source and proposed
destination of an update. Only if the change in test results are
deemed “acceptable” does monotone actually select an update target
to merge into your working copy.
For details on these hooks, see the Hook Reference.
Every monotone database has a set of vars associated with it. Vars are simple configuration variables that monotone refers to in some circumstances; they are used for configuration that monotone needs to be able to modify itself, and that should be per-database (rather than per-user or per-working copy, both of which are supported by monotonerc scripts). Vars are local to a database, and never transferred by netsync.
A var is a name = value pairing inside a domain. Domains define what the vars inside it are used for; for instance, one domain might contain database-global settings, and particular vars inside it would define things like that database's default netsync server. Another domain might contain key fingerprints for servers that monotone has interacted with in the past, to detect man-in-the-middle attacks; the vars inside this domain would map server names to their fingerprints.
You can set vars with the set command, delete them with the unset command, and see them with the ls vars command. See the documentation for these specific commands for more details.
There are several pre-defined domains that monotone knows about:
databasedefault-serverdefault-collectionknown-serversA monotone working copy consists of control files and non-control files. Each type of file can be versioned or non-versioned. These classifications lead to four groups of files:
Control files contain special content formatted for use by monotone. Versioned files are recorded in a monotone database and have their state tracked as they are modified.
If a control file is versioned, it is considered part of the state of the working copy, and will be recorded as a manifest entry. If a control file is not versioned, it is used to manage the state of the working copy, but it not considered an intrinsic part of it.
Most files you manage with monotone will be versioned non-control files. For example, if you keep source code or documents in a monotone database, they are versioned non-control files. Non-versioned, non-control files in your working copy are generally temporary or junk files, such as backups made by editors or object files made by compilers. Such files are ignored by monotone.
Control files are identified by their names. Non-control files can have any name except the names reserved for control files. The names of control files follow a regular pattern:
The following control files are currently used. More control files may be added in the future, but they will follow the patterns given above.
Every certificate has a name. Some names have meaning which is built
in to monotone, others may be used for customization by a particular
user, site, or community. If you wish to define custom certificates,
you should prefix such certificate names with x-. For example,
if you want to make a certificate describing the existence of security
vulnerabilities in a revision, you might wish to create a certificate
called x-vulnerability. Monotone reserves all names which do
not begin with x- for possible internal use. If an x-
certificate becomes widely used, monotone will likely adopt it as a
reserved cert name and standardize its semantics.
Most reserved certificate names have no meaning yet; some do. Usually monotone is also responsible for generating these certificates, so you should generally have no cause to make them yourself. They are described here to help you understand monotone's operation.
The pre-defined, reserved certificate names are:
authorlog command.
branchbranch cert
associates a revision with a branch. The revision is said to be “in
the branch” named by the cert. The cert is generated when you commit
a revision, either directly with the commit command or
indirectly with the merge or propagate commands. The
branch certs are read and directly interpreted by many
monotone commands, and play a fundamental role in organizing work in
any monotone database.
changeloglog command.
commentcomment can
be applied to files as well, and will be shown by the log
command.
datelog command, and
may be used as an additional heuristic or selection criterion in other
commands in the future.
tagcheckout.
testresult0
or 1. It is generated by the testresult command and
represents the results of running a particular test on the underlying
revision. Typically you will make a separate signing key for each test
you intend to run on revisions. This cert influences the
update algorithm.
Some names in monotone are private to your work, such as filenames. Other names are potentially visible outside your project, such as rsa key identifiers or branch names. It is possible that if you choose such names carelessly, you will choose a name which someone else in the world is using, and subsequently you may cause confusion when your work and theirs is received simultaneously by some third party.
We therefore recommend two naming conventions:
[email protected].
net.venge.monotone branch, because the
author owns the DNS domain venge.net.
Monotone contains a mechanism for storing persistent file attributes. These differ from file certificates in an important way: attributes are associated with a path name in your working copy, rather than a particular version of a file. Otherwise they are similar: a file attribute associates a simple name/value pair with a file in your working copy.
The attribute mechanism is motivated by the fact that some people like
to store executable programs in version control systems, and would like
the programs to remain executable when they check out a working copy.
For example, the configure shell script commonly shipped with
many programs should be executable.
Similarly, some people would like to store devices, symbolic links, read-only files, and all manner of extra attributes of a file, not directly related to a file's data content.
Rather than try to extend the manifest file format to accommodate attributes, monotone requires that you place your attributes in a specially named file in the root of your working copy. The file is called .mt-attrs, and it has a simple stanza-based format, for example:
file "analyze_coverage"
execute "true"
file "autogen.sh"
execute "true"
otherattr "bob"
Each stanze of the .mt-attrs file assigns attributes to a file in
your working copy. The first line of each stanza is file
followed by the quoted name of the file you want to assign attributes
to. Each subsequent line is the name of an attribute, followed by a
quoted value for that attribute. Stanzas are separated by blank lines.
As a convenience, you can use the monotone attr command to set
and view the values of these attributes; see Working Copy.
You can tell monotone to automatically take actions based on these
attributes by defining hooks; see the attr_functions entry in
Hook Reference.
Every time your working copy is written to, monotone will look for the .mt-attrs file, and if it exists, run the corresponding hooks registered for each attribute found in the file. This way, you can extend the vocabulary of attributes understood by monotone simply by writing new hooks.
Aside from its special interpretation, the .mt-attrs file is a
normal text file. If you want other people to see your attributes, you
should add and commit the .mt-attrs file in your
working copy. If you make changes to it which conflict with changes
other people make, you will have to resolve those conflicts, as plain
text, just as with any other text file in your working copy.
While the state of your database is logically captured in terms of a packet stream, it is sometimes necessary or desirable (especially while monotone is still in active development) to modify the SQL table layout or storage parameters of your version database, or to make backup copies of your database in plain text. These issues are not properly addressed by generating packet streams: instead, you must use migration or dumping commands.
The monotone db migrate command is used to alter the SQL schema of a database. The schema of a monotone database is identified by a special hash of its generating SQL, which is stored in the database's auxiliary tables. Each version of monotone knows which schema version it is able to work with, and it will refuse to operate on databases with different schemas. When you run the migrate command, monotone looks in an internal list of SQL logic which can be used to perform in-place upgrades. It applies entries from this list, in order, attempting to change the database it has into the database it wants. Each step of this migration is checked to ensure no errors occurred and the resulting schema hashes to the intended value. The migration is attempted inside a transaction, so if it fails — for example if the result of migration hashes to an unexpected value — the migration is aborted.
If more drastic changes to the underlying database are made, such as changing the page size of sqlite, or if you simply want to keep a plain text version of your database on hand, the monotone db dump command can produce a plain ASCII SQL statement which generates the state of your database. This dump can later be reloaded using the monotone db load command.
Note that when reloading a dumped database, the schema of the dumped database is included in the dump, so you should not try to init your database before a load.
Monotone is capable of reading CVS files directly and importing them into a database. This feature is still somewhat immature, but moderately large “real world” CVS trees on the order of 1GB have successfully been imported.
Note however that the machine requirements for CVS trees of this size are not trivial: it can take several hours on a modern system to reconstruct the history of such a tree and calculate the millions of cryptographic certificates involved. We recommend experimenting with smaller trees first, to get a feel for the import process.
We will assume certain values for this example which will differ in your case:
example.net in this example.
[email protected] in this example.
wobbler in this example.
Accounting for these differences at your site, the following is an example procedure for importing a CVS repository “from scratch”, and checking the resulting head version of the import out into a working copy:
$ monotone --db=test.db db init
$ monotone --db=test.db genkey [email protected]
$ monotone --db=test.db --branch=net.example.wobbler cvs_import /usr/local/cvsroot
$ monotone --db=test.db --branch=net.example.wobbler checkout wobber-checkout
This chapter translates common CVS commands into monotone commands. It is an easy alternative to reading through the complete command reference.
$ CVSROOT=:pserver:cvs.foo.com/wobbler
$ cvs -d $CVSROOT checkout -r 1.2
|
$ monotone pull www.foo.com com.foo.wobbler
$ monotone checkout fe37 wobbler
|
The CVS command contacts a network server, retrieves a revision, and stores it in your working copy. There are two cosmetic differences with the monotone command: remote databases are specified by hostnames and collections, and revisions are denoted by sha1 values (or selectors).
There is also one deep difference: pulling revisions into your database is a separate step from checking out a single revision; after you have pulled from a network server, your database will contain several revisions, possibly the entire history of a project. Checking out is a separate step, after communication, which only copies a particular revision out of your database and into a named directory.
$ cvs commit -m 'log message' |
$ monotone commit --message='log message'
$ monotone push www.foo.com com.foo.wobbler
|
As with other networking commands, the communication step with monotone is explicit: committing changes only saves them to the local database. A separate command, push, sends the changes to a remote database.
$ cvs update -d |
$ monotone pull www.foo.com com.foo.wobbler
$ monotone merge
$ monotone update
|
This command, like other networking commands, involves a separate communication step with monotone. The extra command, merge, ensures that the branch your are working on has a unique head. You can omit the merge step if you only want update to examine descendants of your base revision, and ignore other heads on your branch.
$ cvs update -r FOO_TAG -d |
$ monotone update 830ac1a5f033825ab364f911608ec294fe37f7bc
$ monotone update t:FOO_TAG
|
With a revision parameter, the update command operates similarly in monotone and CVS. One difference is that a subsequent commit will be based off the chosen revision in monotone, while a commit in the CVS case is not possible without going back to the branch head again. This version of update can thus be very useful if, for example, you discover that the tree you are working against is somehow broken — you can update to an older non-broken version, and continue to work normally while waiting for the tree to be fixed.
$ cvs diff |
$ monotone diff |
$ cvs diff -r 1.2 -r 1.4 |
$ monotone diff 3e7db 278df |
Monotone's diff command is modeled on that of CVS, so the main features are the same: diff alone prints the differences between your working copy and its base revision, whereas diff accompanied by two revision numbers prints the difference between those two revisions. The major difference between CVS and monotone here is that monotone's revision numbers are revision IDs, so the diff command prints the difference between the two entire trees.
$ cvs status |
$ monotone status |
This command operates similarly in monotone and CVS. The only major difference is that monotone's status command always gives a status of the whole tree, and outputs a more compact summary than CVS.
$ cvs add dir
$ cvs add dir/subdir
$ cvs add dir/subdir/file.txt
|
$ monotone add dir/subdir/file.txt |
Monotone does not explicitly store directories, so adding a file only involves adding the file's complete path, including any directories. Directories are created as needed, and empty directories are ignored.
$ rm file.txt
$ cvs remove file.txt
|
$ monotone drop file.txt |
Monotone does not require that you erase a file from the working copy before you drop it. Dropping a file merely removes its entry in the manifest of the current revision.
$ cvs init -d /path/to/repository |
$ monotone db init --db=/path/to/database.db |
Monotone's “repository” is a single-file database, which is created and initialized by this command. This file is only ever used by you, and does not need to be in any special location, or readable by other users.
Monotone has a large number of commands. To help navigate through them all, commands are grouped into logical categories.
84e2c30a2571bd627918deee1e6613d34e64a29e Makefile
c61af2e67eb9b81e46357bb3c409a9a53a7cdfc6 include/hello.h
97dfc6fd4f486df95868d85b4b81197014ae2a84 src/hello.c
Then the following files are created:
directory/Makefile
directory/include/hello.h
directory/src/hello.c
If you wish to checkout in the current directory, you can supply the special name . (a single period) for directory.
If no id is provided, as in the latter two commands, you
must provide a branchname; monotone will attempt to infer
id as the unique head of branchname if it exists.
Note that this command only works if id has exactly one ancestor.
The “heads” of a branch is the set of revisions which are members of
the branch, but which have no descendants. These revisions are
generally the “newest” revisions committed by you or your
colleagues, at least in terms of ancestry. The heads of a branch may
not be the newest revisions, in terms of time, but synchronization of
computer clocks is not reliable, so monotone usually ignores time.
Merging is performed by repeated pairwise merges: two heads are
selected, then their least common ancestor is located in the ancestry
graph and these 3 revisions are provided to the built-in 3-way merge
algorithm. The process then repeats for each additional head, using
the result of each previous merge as an input to the next.
The purpose of propagate is to copy all the changes on
sourcebranch, since the last propagate, to
destbranch. This command supports the idea of making separate
branches for medium-length development activities, such as
maintenance branches for stable software releases, trivial bug fix
branches, public contribution branches, or branches devoted to the
development of a single module within a larger project.
propagate or merge
give you. For instance, if you have a branch with three heads, and you
only want to merge two of them, you can use this command. Or if you
have a branch with two heads, and you want to propagate one of them to
another branch, again, you can use this command. If the optional
ancestor argument is given, the merge uses that revision as the
common ancestor instead of the default ancestor.
While this command places an “add” entry on your work list, it does
not immediately affect your database. When you commit your
working copy, monotone will use the work list to build a new revision,
which it will then commit to the database. The new revision will have
any added entries inserted in its manifest.
While this command places a “drop” entry on your work list, it does
not immediately affect your database. When you commit your
working copy, monotone will use the work list to build a new revision,
which it will then commit to the database. The new revision will have
any dropped entries removed from its manifest.
While this command places a “rename” entry on your work list, it
does not immediately affect your database. When you commit
your working copy, monotone will use the work list to build a new
revision, which it will then commit to the database. The new revision
will have any renamed entries in its manifest adjusted to their new
names.
For each edited file, a delta is copied into the database. Then the newly constructed manifest is recorded (as a delta) and finally the new revision. Once all these objects are recorded in you database, commit overwrites the MT/revision file with the new revision ID, and deletes the MT/work file.
Specifying pathnames to commit restricts the set of changes that are visible and results in only a partial commit of the working copy. Changes to files not included in the specified set of pathnames will be ignored and will remain in the working copy until they are included in a future commit. With a partial commit, only the relevant entries in the MT/work file will be removed and other entries will remain for future commits.
From within a subdirectory of the working copy the commit command will, by default, include all changes in the working copy. Specifying only the pathname "." will restrict commit to files changed within the current subdirectory of the working copy.
The MT/log file can be edited by the user during their daily work
to record the changes made to the working copy. When running the
commit command without a logmsg supplied, the contents
of the MT/log file will be read and passed to the Lua hook
edit_comment as a second parameter named user_log_content.
If the commit is successful, the MT/log file is cleared of
all content making it ready for another edit/commit cycle.
The commit command also synthesizes a number of certificates, which it attaches to the new manifest version and copies into your database:
author cert, indicating the person responsible for the changes
leading to the new revision.
branch cert, indicating the branch the committed revision
belongs to.
date cert, indicating when the new revision was created.
changelog cert, containing the “log message” for these
changes. If you provided logmsg on the command line, this text
will be used, otherwise commit will run the Lua hook
edit_comment (commentary, user_log_content), which
typically invokes an external editor program, in which you can compose
and/or review your log message for the change.
If files or directories are given as arguments, only those files and directories are affected instead of the entirety of your working copy.
From within a subdirectory of the working copy the revert
command will, by default, revert all changes in the working copy.
Specifying only the pathname "." will restrict revert to files
changed within the current subdirectory of the working copy. Caution
should be used when reverting files to ensure that the correct set of
files is reverted.
With an explicit revision argument, the command uses that revision as the update target instead of finding an acceptable candidate.
The effect is always to take whatever changes you have made in the working copy, and to “transpose” them onto a new revision, using monotone's 3-way merge algorithm to achieve good results. Note that with the explicit revision argument, it is possible to update “backwards” or “sideways” in history — for example, reverting to an earlier revision, or if your branch has two heads, updating to the other. In all cases, the end result will be whatever revision you specified, with your local changes (and only your local changes) applied.
The network address specified in each case should be the same: a host name to listen on, or connect to, optionally followed by a colon and a port number. The collection parameter indicates a set of branches to exchange; every branch for which collection is a prefix will be indexed and made available for synchronization.
For example, supposing Bob and Alice wish to synchronize their
net.venge.monotone.win32 and net.venge.monotone.i18n
branches. Supposing Alice's computer has hostname
alice.someisp.com, then Alice might run:
$ monotone serve alice.someisp.com net.venge.monotone
And Bob might run
$ monotone sync alice.someisp.com net.venge.monotone
When the operation completes, all branches beginning with
net.venge.monotone will be synchronized between Alice and Bob's
databases.
The pull, push, and sync commands only require you pass address and collection the first time you use one of them; monotone will memorize this use and in the future default to the same server and collection. For instance, if Bob wants to sync with Alice again, he can simply run:
$ monotone sync
Of course, he can still sync with other people and other
branches by passing an address or address plus collection on the command
line; this will not affect his default affinity for Alice. If you ever
do want to change your defaults, use monotone unset database
default-server or monotone unset database default-collection;
these will clear your defaults, and cause them to be reset to the next
person you netsync with.
Specifying optional pathname... arguments to the status command restricts the set of changes that are visible and results in only a partial status of the working copy. Changes to files not included in the specified set of pathnames will be ignored.
From within a subdirectory of the working copy the status
command will, by default, include all changes in the working
copy. Specifying only the pathname "." will restrict status
to files changed within the current subdirectory of the working copy.
file, manifest or
revision IDs depending on which variant is used. For
example, suppose you enter this command and get this result:
$ monotone complete manifest fa36
fa36deead87811b0e15208da2853c39d2f6ebe90
fa36b76dd0139177b28b379fe1d56b22342e5306
fa36965ec190bee14c5afcac235f1b8e2239bb2a
Then monotone is telling you that there are 3 manifests it knows
about, in its database, which begin with the 4 hex digits
fa36. This command is intended to be used by programmable
completion systems, such as those in bash and zsh.
With one --revision option, diff will print the differences between the revision id and the current revision in the working copy. With two --revision options diff will print the differences between revisions id1 and id2, ignoring any working copy. Note that no pathname... arguments may be specified to restrict the diff output in this case. Restrictions may only be applied to the current, in-progress, working copy revision.
In all cases, monotone will print a textual summary – identical to
the summary presented by monotone status – of the logical
differences between revisions in lines proceeding the diff. These
lines begin with a single hash mark #, and should be ignored by
a program processing the diff, such as patch.
Specifying pathnames to the diff command restricts the set of changes that are visible and results in only a partial diff of the working copy. Changes to files not included in the specified set of pathnames will be ignored.
From within a subdirectory of the working copy the diff
command will, by default, include all changes in the working
copy. Specifying only the pathname "." will restrict diff
to files changed within the current subdirectory of the working copy.
ok or bad
For example, this command lists the certificates associated with a particular version of monotone itself, in the monotone development branch:
$ ./monotone list certs 4a96
monotone: expandeding partial id '4a96'
monotone: expanded to '4a96a230293456baa9c6e7167cafb3c5b52a8e7f'
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : author
Value : [email protected]
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : branch
Value : monotone
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : date
Value : 2003-10-17T03:20:27
-----------------------------------------------------------------
Key : [email protected]
Sig : ok
Name : changelog
Value : 2003-10-16 graydon hoare <[email protected]>
:
: * sanity.hh: Add a const version of idx().
: * diff_patch.cc: Change to using idx() everywhere.
: * cert.cc (find_common_ancestor): Rewrite to recursive
: form, stepping over historic merges.
: * tests/t_cross.at: New test for merging merges.
: * testsuite.at: Call t_cross.at.
:
If pattern is provided, it is used as a glob to limit the keys
listed. Otherwise all keys in your database are listed.
Specifying pathnames to the list known command restricts the set of paths that are searched for manifest files. Files not included in the specified set of pathnames will not be listed.
From within a subdirectory of the working copy the list
known command will, by default, search the entire working copy.
Specifying only the pathname "." will restrict the search for unknown
files to the current subdirectory of the working copy.
Specifying pathnames to the list unknown command restricts the set of paths that are searched for unknown files. Unknown files not included in the specified set of pathnames will not be listed.
From within a subdirectory of the working copy the list
unknown command will, by default, search the entire working copy.
Specifying only the pathname "." will restrict the search for unknown
files to the current subdirectory of the working copy.
ignore_file
(filename) hook.
Specifying pathnames to the list ignored command restricts the set of paths that are searched for ignored files. Ignored files not included in the specified set of pathnames will not be listed.
From within a subdirectory of the working copy the list
ignored command will, by default, search the entire working copy.
Specifying only the pathname "." will restrict the search for ignored
files to the current subdirectory of the working copy.
Specifying pathnames to the list missing command restricts the set of paths that are searched for missing files. Missing files not included in the specified set of pathnames will not be listed.
From within a subdirectory of the working copy the list missing command will, by default, search the entire working copy. Specifying only the pathname "." will restrict the search for missing files to the current subdirectory of the working copy.
non_blocking_rng_ok() returns true, the key
generation will use an unlimited random number generator (such as
/dev/urandom), otherwise it will use a higher quality random
number generator (such as /dev/random) but might run slightly
slower.
The private half of the key is stored in an encrypted form, using the
symmetric cipher arc4, so that anyone accidentally reading your
database cannot extract your private key and use it. You must provide
a passphrase for your key when it is generated, which is used to key
the arc4 cipher. In the future you will need to enter this
passphrase again each time you sign a certificate, which happens every
time you commit to your database. You can tell monotone to
automatically use a certain passphrase for a given key using the
get_passphrase(keypair_id), but this significantly
increases the risk of a key compromise on your local computer. Be
careful using this hook.
stdin.
get_revision_cert_trust (see Hook Reference). You pass it
a revision id, a certificate name, a certificate value, and one or more
key ids, and it will tell you whether, under your current settings,
Monotone would trust a cert on that revision with that value signed by
those keys.
monotone cert id branch
branchname where branchname is the current branch name
(either deduced from the working copy or from the --branch
option).
monotone cert id
comment comment. If comment is not provided, it is read
from stdin.
monotone cert id tag
tagname.
monotone cert id
testresult 0 or monotone cert id testresult 1.
Monotone can produce and consume data in a convenient, portable form called packets. A packet is a sequence of ASCII text, wrapped at 70-columns and easily sent through email or other transports. If you wish to manually transmit a piece of information – for example a public key – from one monotone database to another, it is often convenient to read and write packets.
Note: earlier versions of monotone queued and replayed packet streams for their networking system. This older networking system is deprecated and will be removed in a future version, as the netsync protocol has several properties which make it advantageous as a communication system. However, the packet i/o facility will remain in monotone as a utility for moving individual data items around manually.
rcert packet for each cert in your
database associated with id. These can be used to transport
certificates safely between monotone databases.
fdata, mdata or rdata
packet for the file, manifest or revision id in your database.
These can be used to transport files, manifests or revisions, in their
entirety, safely between monotone databases.
fdelta or mdelta packet for
the differences between file or manifest versions id1 and
id2, in your database. These can be used to transport file or
manifest differences safely between monotone databases.
privkey or pubkey packet for
the rsa key keyid. These can be used to transport public or
private keys safely between monotone databases.
stdin and applies them to your
database.
Note that when reloading a dumped database, the schema of the dumped
database is included in the dump, so you should not try to
init your database before a load.
If you have important information in your database, you should back up
a copy of it before migrating, in case there is an untrapped error
during migration.
However, it's also nice to notice such problems early, and in rarely used parts of history, while you still have backups. That's what this command is for. It systematically checks the database dbfile to ensure that it is complete and consistent. The following problems are detected:
This command also verifies that the sha1 of every file, manifest,
and revision is correct.
This section contains subcommands of the monotone automate
command, used for scripting monotone. All give output on stdout; they
may also give useful chatter on stderr, including warnings and error
messages.
automate
command; minor number increments whenever any change is made (but is
reset when major number increments).
1.2
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
The output does not include rev1, rev2, etc., except that if
rev2 is itself a descendent of rev1, then rev2 will be
included in the output.
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
28ce076c69eadb9b1ca7bdf9d40ce95fe2f29b61
75156724e0e2e3245838f356ec373c50fa469f1f
,v. Monotone parses them directly and inserts them into your
database. Note that this does not do any revision reconstruction, and
is only useful for debugging.
Monotone's behavior can be customized and extended by writing hook functions, which are written in the Lua programming language. At certain points in time, when monotone is running, it will call a hook function to help it make a decision or perform some action. If you provide a hook function definition which suits your preferences, monotone will execute it. This way you can modify how monotone behaves.
You can put new definitions for any of these hook functions in a file $HOME/.monotonerc, or in your working copy in MT/monotonerc, both of which will be read every time monotone runs. Definitions in MT/monotonerc shadow (override) definitions made in your $HOME/.monotonerc. You can also tell monotone to interpret extra hook functions from any other file using the --rcfile=file option; hooks defined in files specified on the command-line will shadow hooks from the the automatic files.
The remainder of this section documents the existing hook functions and their default definitions.
note_commit (new_id, certs)Note that since the certs table does not contain cryptographic
or trust information, and only contains one entry per cert name, it is
an incomplete source of information about the committed version. This
hook is only intended as an aid for integrating monotone with informal
commit-notification systems such as mailing lists or news services. It
should not perform any security-critical operations.
get_branch_key (branchname)get_passphrase (keypair_id)"[email protected]". This hook has no default definition. If
this hook is not defined or returns false, monotone will prompt you for
a passphrase each time it needs to use a private key.
get_author (branchname)author certificates when you commit changes to
branchname. Generally this hook remains undefined, and monotone
selects your signing key name for the author certificate. You can use
this hook to override that choice, if you like.
This hook has no default definition, but a possible definition might be:
function get_author(branchname)
local user = os.getenv("USER")
local host = os.getenv("HOSTNAME")
if ((user == nil) or (host == nil)) then return nil end
return string.format("%s@%s", user, host)
end
edit_comment (commentary, user_log_message)changelog certificate, automatically generated when you commit
changes.
The contents of MT/log are read and passed as user_log_message. This allows you do document your changes as you proceed instead of waiting until you are ready to commit. Upon a successful commit, the contents of MT/log are erased setting the system up for another edit/commit cycle.
The default definition of this hook is:
function edit_comment(commentary, user_log_message)
local exe = "vi"
local visual = os.getenv("VISUAL")
if (visual ~= nil) then exe = visual end
local editor = os.getenv("EDITOR")
if (editor ~= nil) then exe = editor end
local tmp, tname = temp_file()
if (tmp == nil) then return nil end
commentary = "MT: " .. string.gsub(commentary, "\n", "\nMT: ")
tmp:write(user_log_message)
tmp:write(commentary)
io.close(tmp)
if (os.execute(string.format("%s %s", exe, tname)) ~= 0) then
os.remove(tname)
return nil
end
tmp = io.open(tname, "r")
if (tmp == nil) then os.remove(tname); return nil end
local res = ""
local line = tmp:read()
while(line ~= nil) do
if (not string.find(line, "^MT:")) then
res = res .. line .. "\n"
end
line = tmp:read()
end
io.close(tmp)
os.remove(tname)
return res
end
persist_phrase_ok ()true if you want monotone to remember the passphrase of
a private key for the duration of a single command, or false if
you want monotone to prompt you for a passphrase for each certificate
it generates. Since monotone often generates several certificates in
quick succession, unless you are very concerned about security you
probably want this hook to return true.
The default definition of this hook is:
function persist_phrase_ok()
return true
end
non_blocking_rng_ok ()true if you are willing to let monotone use the
system's non-blocking random number generator, such as
/dev/urandom, for generating random values during cryptographic
operations. This diminishes the cryptographic strength of such
operations, but speeds them up. Returns false if you want to
force monotone to always use higher quality random numbers, such as
those from /dev/random.
The default definition of this hook is:
function non_blocking_rng_ok()
return true
end
get_netsync_read_permitted (collection, identity)true if a peer authenticated as key identity
should be allowed to read from your database certs, revisions,
manifests, and files associated with the netsync index
collection; otherwise false. This hook has no default
definition, therefore the default behavior is to deny all reads.
Note that the identity value is a key id (such as
“[email protected]”) but will correspond to a unique
key fingerprint (hash) in your database. Monotone will not permit two
keys in your database to have the same id. Make sure you confirm the
key fingerprints of each key in your database, as key id strings are
“convenience names”, not security tokens.
get_netsync_anonymous_read_permitted (collection)get_netsync_read_permitted
except that it is called when a connecting client requests anonymous
read access to a collection. There is no corresponding anonymous write
access hook. This hook has no default definition, therefore the
default behavior is to deny all anonymous reads.
get_netsync_write_permitted (collection, identity)true if a peer authenticated as key identity
should be allowed to write into your database certs, revisions,
manifests, and files associated with the netsync index
collection; otherwise false. This hook has no default
definition, therefore the default behavior is to deny all writes.
Note that the identity value is a key id (such as
“[email protected]”) but will correspond to a unique
key fingerprint (hash) in your database. Monotone will not permit two
keys in your database to have the same id. Make sure you confirm the
key fingerprints of each key in your database, as key id strings are
“convenience names”, not security tokens.
ignore_file (filename)true if filename should be ignored while adding,
dropping, or moving files. Otherwise returns false. This is
most important when performing recursive actions on directories, which
may affect multiple files simultaneously. The default definition of
this hook is:
function ignore_file(name)
if (string.find(name, "%.a$")) then return true end
if (string.find(name, "%.so$")) then return true end
if (string.find(name, "%.o$")) then return true end
if (string.find(name, "%.la$")) then return true end
if (string.find(name, "%.lo$")) then return true end
if (string.find(name, "%.aux$")) then return true end
if (string.find(name, "%.bak$")) then return true end
if (string.find(name, "%.orig$")) then return true end
if (string.find(name, "%.rej$")) then return true end
if (string.find(name, "%~$")) then return true end
if (string.find(name, "/core$")) then return true end
if (string.find(name, "^CVS/")) then return true end
if (string.find(name, "/CVS/")) then return true end
if (string.find(name, "^%.svn/")) then return true end
if (string.find(name, "/%.svn/")) then return true end
if (string.find(name, "^SCCS/")) then return true end
if (string.find(name, "/SCCS/")) then return true end
return false;
end
ignore_branch (branchname)true if branchname should be ignored while listing
branches. Otherwise returns false. This hook has no default
definition, therefore the default behavior is to list all branches.
get_revision_cert_trust (signers, id, name, val)The default definition of this hook simply returns true, which
corresponds to a form of trust where every key which is defined in
your database is trusted. This is a weak trust setting; you
should change it to something stronger. A possible example of a
stronger trust function (along with a utility function for computing
the intersection of tables) is the following:
function intersection(a,b)
local s={}
local t={}
for k,v in pairs(a) do s[v] = 1 end
for k,v in pairs(b) do if s[v] ~= nil then table.insert(t,v) end end
return t
end
function get_revision_cert_trust(signers, id, name, val)
local trusted_signers = { "[email protected]",
"[email protected]",
"[email protected]" }
local t = intersection(signers, trusted_signers)
if t == nil then return false end
if (name ~= "ancestor" and table.getn(t) >= 1)
or (name == "ancestor" and table.getn(t) >= 2)
then
return true
else
return false
end
end
In this example, any revision certificate is trusted if it is signed
by at least one of three “trusted” keys, unless it is an
ancestor certificate, in which case it must be signed by
two or more trusted keys. This is one way of requiring that
ancestry assertions go through an extra “reviewer” before they are
accepted.
accept_testresult_change (old_results, new_results)true if you consider an update from the
version carrying the old_results to the version carrying the
new_results to be acceptable.
The default definition of this hook follows:
function accept_testresult_change(old_results, new_results)
for test,res in pairs(old_results)
do
if res == true and new_results[test] ~= true
then
return false
end
end
return true
end
This definition accepts only those updates which preserve the set of
true test results from update source to target. If no rest
results exist, this hook has no affect; but once a true test
result is present, future updates will require it. If you want a more
lenient behavior you must redefine this hook.
merge2 (left, right) function merge2(left, right)
local lfile = nil
local rfile = nil
local outfile = nil
local data = nil
lfile = write_to_temporary_file(left)
rfile = write_to_temporary_file(right)
outfile = write_to_temporary_file("")
if lfile ~= nil and
rfile ~= nil and
outfile ~= nil
then
local cmd = nil
if program_exists_in_path("xxdiff") then
cmd = merge2_xxdiff_cmd(lfile, rfile, outfile)
elseif program_exists_in_path("emacs") then
cmd = merge2_emacs_cmd("emacs", lfile, rfile, outfile)
elseif program_exists_in_path("xemacs") then
cmd = merge2_emacs_cmd("xemacs", lfile, rfile, outfile)
end
if cmd ~= nil
then
io.write(
string.format("executing external 2-way merge command: %s\n",
cmd))
os.execute(cmd)
data = read_contents_of_file(outfile)
else
io.write("no external 2-way merge command found")
end
end
os.remove(lfile)
os.remove(rfile)
os.remove(outfile)
return data
end
merge3 (ancestor, left, right) function merge3(ancestor, left, right)
local afile = nil
local lfile = nil
local rfile = nil
local outfile = nil
local data = nil
lfile = write_to_temporary_file(left)
afile = write_to_temporary_file(ancestor)
rfile = write_to_temporary_file(right)
outfile = write_to_temporary_file("")
if lfile ~= nil and
rfile ~= nil and
afile ~= nil and
outfile ~= nil
then
local cmd = nil
if program_exists_in_path("xxdiff") then
cmd = merge3_xxdiff_cmd(lfile, afile, rfile, outfile)
elseif program_exists_in_path("emacs") then
cmd = merge3_emacs_cmd("emacs", lfile, afile, rfile, outfile)
elseif program_exists_in_path("xemacs") then
cmd = merge3_emacs_cmd("xemacs", lfile, afile, rfile, outfile)
end
if cmd ~= nil
then
io.write(
string.format("executing external 3-way merge command: %s\n",
cmd))
os.execute(cmd)
data = read_contents_of_file(outfile)
else
io.write("no external 3-way merge command found")
end
end
os.remove(lfile)
os.remove(rfile)
os.remove(afile)
os.remove(outfile)
return data
end
expand_selector (str)a: for
authors or d: for dates. Expansion may also mean recognizing
and interpreting special words such as yesterday or 6
months ago and converting them into well formed selectors. For more
detail on the use of selectors, see Selectors. The default
definition of this hook is:
function expand_selector(str)
-- simple date patterns
if string.find(str, "^19%d%d%-%d%d")
or string.find(str, "^20%d%d%-%d%d")
then
return ("d:" .. str)
end
-- something which looks like an email address
if string.find(str, "[%w%-_]+@[%w%-_]+")
then
return ("a:" .. str)
end
-- something which looks like a branch name
if string.find(str, "[%w%-]+%.[%w%-]+")
then
return ("b:" .. str)
end
-- a sequence of nothing but hex digits
if string.find(str, "^%x+$")
then
return ("i:" .. str)
end
-- "yesterday", the source of all hangovers
if str == "yesterday"
then
local t = os.time(os.date('!*t'))
return os.date("d:%F", t - 86400)
end
-- "CVS style" relative dates such as "3 weeks ago"
local trans = {
minute = 60;
hour = 3600;
day = 86400;
week = 604800;
month = 2678400;
year = 31536000
}
local pos, len, n, type = string.find(str, "(%d+)
([minutehordaywk]+)s? ago")
if trans[type] ~= nil
then
local t = os.time(os.date('!*t'))
return os.date("d:%F", t - (n * trans[type]))
end
return nil
end
get_system_linesep ()CR, LF, or
CRLF. The system line separator may be used when reading or
writing data to the terminal, or otherwise interfacing with the user.
The system line separator is not used to convert files in the working
copy; use get_linesep_conv for converting line endings in the
working copy.
This hook has no default definition. For more information on line
ending conversion, see the section on Internationalization.
get_linesep_conv (filename)CR, LF, or
CRLF.
When filename is read from the working copy, it is run through line ending conversion from the external form to the internal form. When filename is written to the working copy, it is run through line ending conversion from the internal form to the external form. sha1 values are calculated from the internal form of filename. It is your responsibility to decide which line ending conversions your work will use.
This hook has no default definition; monotone's default behavior is to
keep external and internal forms byte-for-byte identical. For more
information on line ending conversion, see the section on
Internationalization.
get_charset_conv (filename)When filename is read from the working copy, it is run through character set conversion from the external form to the internal form. When filename is written to the working copy, it is run through character set conversion from the internal form to the external form. sha1 values are calculated from the internal form of filename. It is your responsibility to decide which character set conversions your work will use.
This hook has no default definition; monotone's default behavior is to
keep external and internal forms byte-for-byte identical. For more
information on character set conversion, see the section on
Internationalization.
attr_functions [attribute] (filename, value)attr_functions, at table
entry attribute, is a function taking a file name filename
and a attribute value value. The function should “apply” the
attribute to the file, possibly in a platform-specific way.
Persistent attributes are stored in the .mt-attrs, in your working copy and manifest. If such a file exists, hook functions from this table are called for each triple found in the file, after any command which modifies the working copy. This facility can be used to extend monotone's understanding of files with platform-specific attributes, such as permission bits, access control lists, or special file types.
By default, there is only one entry in this table, for the execute
attribute. Its definition is:
attr_functions["execute"] =
function(filename, value)
if (value == "true") then
os.execute(string.format("chmod +x %s", filename))
end
end
This chapter describes some “special” issues which are not directly related to monotone's use, but which are occasionally of interest to people researching monotone or trying to learn the specifics of how it works. Most users can ignore these sections.
Monotone initially dealt with only ASCII characters, in file path names, certificate names, key names, and packets. Some conservative extensions are provided to permit internationalized use. These extensions can be summarized as follows:
The remainder of this section is a precise specification of monotone's internationalization behavior.
get_charset_conv which takes a filename
and returns a table of two strings: the first represents the
"internal" (database) charset, the second represents the "external"
(file system) charset.
0x0D, 0x0A, or the pair 0x0D 0x0A) from one
convention to another. Per-file line ending conversion is specified by
a Lua hook get_linesep_conv which takes a filename and returns
a table of two strings: the first represents the "internal" (database)
line ending convention, the second represents the "external"
(file system) line ending convention. each string should be one of the
three strings "CR", "LF", or "CRLF".
Note that Line ending conversion is always performed on the internal
character set, when both character set and line ending conversion are
enabled; this behavior is meant to encourage the use of the monotone's
“normal form” (UTF-8, '\n') as an internal form for your source
files, when working with multiple external forms. Also note that line
ending conversion only works on character encodings with the specific
code bytes described above, such as ASCII, ISO-8859x, and UTF-8.
get_system_linesep hook. No hooks exist for adjusting the
system character set, since the system character set must be known
during command-line argument processing, before any Lua hooks are
loaded.
Monotone's normal form is the UTF-8 character set and the 0x0A
(LF) line ending form. This form is used in any files monotone needs
to read, write, and interpret itself, such as: MT/revision,
MT/work, MT/options, .mt-attrs
0x2D,
0x30..0x39, 0x41..0x5A, and 0x61..0x7A.
{ACE-prefix}{LDH-sanitized(punycode(nameprep(UTF-8-string)))}
It is important to understand that IDNA encoding does not preserve the input string: it both prohibits a wide variety of possible strings and normalizes non-equal strings to supposedly "equivalent" forms.
By default, monotone does not decode IDNA when printing to the
console (IDNA names are ASCII, which is a subset of UTF-8, so this
normal form conversion can still apply, albeit oddly). this behavior
is to protect users against security problems associated with
malicious use of "similar-looking" characters. If the hook
display_decoded_idna returns true, IDNA names are decoded for
display.
0x5C '\' path separator to 0x2F '/'. This extra
processing is performed by boost::filesystem.
0x2F (ASCII / ), and
without a leading or trailing 0x2F.
0x2F and any ASCII "control codes"
(0x00..0x1F and 0x7F).
sha1sum will produce
different results than those entries shown in a corresponding manifest.
UI messages are displayed via calls to gettext().
Host names are read on the command-line and subject to normal form
conversion. Host names are then split at 0x2E (ASCII '.'), each
component is subject to IDNA encoding, and the components are
rejoined.
After processing, host names are stored internally as ASCII. The
invariant is that a host name inside monotone contains only sequences
of LDH separated by 0x2E.
Read on the command line and subject to normal form conversion and IDNA encoding as a single component. The invariant is that a cert name inside monotone is a single LDH ASCII string.
Cert values may be either text or binary, depending on the return
value of the hook cert_is_binary. If binary, the cert value is
never printed to the screen (the literal string "<binary>" is
displayed, instead), and is never subjected to line ending or
character conversion. If text, the cert value is subject to normal
form conversion, as well as having all UTF-8 codes corresponding to
ASCII control codes (0x0..0x1F and 0x7F) prohibited in
the normal form, except 0x0A (ASCII LF).
Read on the command line and subject to normal form conversion and IDNA encoding as a single component. The invariant is that a var domain inside monotone is a single LDH ASCII string.
Var names and values are assumed to be text, and subject to normal form conversion.
Read on the command line and subject to normal form conversion and
IDNA encoding as an email address (split and joined at '.' and '@'
characters). The invariant is that a key name inside monotone contains
only LDH, 0x2E (ASCII '.') and 0x40 (ASCII '@')
characters.
Packets are 7-bit ASCII. The characters permitted in packets are the union of these character sets:
Now uses 0x0A (ASCII LF) as a delimiter, to permit 0x20 in filenames. This may change in the future.
Some proponents of a competing, proprietary version control system have suggested, in a usenix paper, that the use of a cryptographic hash function such as sha1 as an identifier for a version is unacceptably unsafe. This section addresses the argument presented in that paper and describes monotone's additional precautions.
To summarize our position:
The paper displays a fundamental lack of understanding about what a cryptographic hash function is, and how it differs from a normal hash function. Furthermore it confuses accidental collision with attack scenarios, and mixes up its analysis of the risk involved in each. We will try to untangle these issues here.
A cryptographic hash function such as sha1 is more than just a uniform spread of inputs to an output range. Rather, it must be designed to withstand attempts at:
Collision is the problem the paper is concerned with. Formally, an n-bit cryptographic hash should cost 2^n work units to collide against a given value, and sqrt(2^n) tries to find a random pair of colliding values. This latter probability is sometimes called the hash's “birthday paradox probability”.
One way of measuring these bounds is by measuring how single-bit changes in the input affect bits in the hash output. The sha1 hash has a strong avalanche property, which means that flipping any one bit in the input will cause on average half the 160 bits in the output code to change. The fanciful val1 hash presented in the paper does not have such a property — flipping its first bit when all the rest are zero causes no change to any of the 160 output bits — and is completely unsuited for use as a cryptographic hash, regardless of the general shape of its probability distribution.
The paper also suggests that birthday paradox probability cannot be used to measure the chance of accidental sha1 collision on “real inputs”, because birthday paradox probability assumes a uniformly random sample and “real inputs” are not uniformly random. The paper is wrong: the inputs to sha1 are not what is being measured (and in any case can be arbitrarily long); the collision probability being measured is of output space. On output space, the hash is designed to produce uniformly random spread, even given nearly identical inputs. In other words, it is a primary design criterion of such a hash that a birthday paradox probability is a valid approximation of its collision probability.
The paper's characterization of risk when hashing “non-random inputs” is similarly deceptive. It presents a fanciful case of a program which is storing every possible 2kb block in a file system addressed by sha1 (the program is trying to find a sha1 collision). While this scenario will very likely encounter a collision somewhere in the course of storing all such blocks, the paper neglects to mention that we only expect it to collide after storing about 2^80 of the 2^16384 possible such blocks (not to mention the requirements for compute time to search, or disk space to store 2^80 2kb blocks).
Noting that monotone can only store 2^41 bytes in a database, and thus probably some lower number (say 2^32 or so) active rows, we consider such birthday paradox probability well out of practical sight. Perhaps it will be a serious concern when multi-yottabyte hard disks are common.
Setting aside accidental collisions, then, the paper's underlying theme of vulnerability rests on the assertion that someone will break sha1. Breaking a cryptographic hash usually means finding a way to collide it trivially. While we note that sha1 has in fact resisted attempts at breaking for 8 years already, we cannot say that it will last forever. Someone might break it. We can say, however, that finding a way to trivially collide it only changes the resistance to active attack, rather than the behavior of the hash on benign inputs.
Therefore the vulnerability is not that the hash might suddenly cease to address benign blocks well, but merely that additional security precautions might become a requirement to ensure that blocks are benign, rather than malicious. The paper fails to make this distinction, suggesting that a hash becomes “unusable” when it is broken. This is plainly not true, as a number of systems continue to get useful low collision hashing behavior — just not good security behavior — out of “broken” cryptographic hashes such as MD4.
Perhaps our arguments above are unconvincing, or perhaps you are the sort of person who thinks that practice never lines up with theory. Fair enough. Below we present practical procedures you can follow to compensate for the supposed threats presented in the paper.
A successful collision attack on sha1, as mentioned, does not disrupt the probability features of sha1 on benign blocks. So if, at any time, you believe sha1 is “broken”, it does not mean that you cannot use it for your work with monotone. It means, rather, that you cannot base your trust on sha1 values anymore. You must trust who you communicate with.
The way around this is reasonably simple: if you do not trust sha1 to prevent malicious blocks from slipping into your communications, you can always augment it by enclosing your communications in more security, such as tunnels or additional signatures on your email posts. If you choose to do this, you will still have the benefit of self-identifying blocks, you will simply cease to trust such blocks unless they come with additional authentication information.
If in the future sha1 (or, indeed, rsa) becomes accepted as broken we will naturally upgrade monotone to a newer hash or public key scheme, and provide migration commands to recalculate existing databases based on the new algorithm.
Similarly, if you do not trust our vigilance in keeping up to date
with cryptography literature, you can modify monotone to use any
stronger hash you like, at the cost of isolating your own
communications to a group using the modified version. Monotone is free
software, and runs atop crypto++, so it is both legal and
relatively simple to change it to use some other algorithm.
As described in Historical records, monotone revisions contain the sha1 hashes of their predecessors, which in turn contain the sha1 hashes of their predecessors, and so on until the beginning of history. This means that it is mathematically impossible to modify the history of a revision, without some way to defeat sha1. This is generally a good thing; having immutable history is the point of a version control system, after all, and it turns out to be very important to building a distributed version control system like monotone.
It does have one unfortunate consequence, though. It means that in the rare occasion where one needs to change a historical revision, it will change the sha1 of that revision, which will change the text of its children, which will change their sha1s, and so on; basically the entire history graph will diverge from that point (invalidating all certs in the process).
In practice there are two situations where this might be necessary:
If either of these events occur, we will provide migration commands
and explain how to use them for the situation in question; this much
is necessarily somewhat unpredictable. In the past we've used the
db rebuild command, which extracts the ancestry graph from the
database and then recreates revisions from the manifests only — this
preserves the contents of each snapshot, but breaks tracking of file
identity across renames — and then reissues all existing certs that
you trust, signed with your key.2
While the db rebuild command can reconstruct the ancestry graph
in your database, there are practical problems which arise when
working in a distributed work group. For example, suppose our group
consists of the fictional developers Jim and Beth, and they need to
rebuild their ancestry graph. Jim performs a rebuild, and sends Beth
an email telling her that he has done so, but the email gets caught by
Beth's spam filter, she doesn't see it, and she blithely syncs her
database with Jim's. This creates a problem: Jim and Beth have
combined the pre-rebuild and post-rebuild databases. Their databases
now contain two complete, parallel (but possibly overlapping) copies
of their project's ancestry. The “bad” old revisions that they were
trying to get rid of are still there, mixed up with the “good” new
revisions.
To prevent such messy situations, monotone keeps a table of branch epochs in each database. An epoch is just a large bit string associated with a branch. Initially each branch's epoch is zero. Most monotone commands ignore epochs; they are relevant in only two circumstances:
Thus, when a user rebuilds their ancestry graph, they select a new epoch and thus effectively disassociate with the group of colleagues they had previously been communicating with. Other members of that group can then decide whether to follow the rebuild user into a new group — by pulling the newly rebuilt ancestry — or to remain behind in the old group.
In our example, if Jim and Beth have epochs, Jim's rebuild creates a new epoch for their branch, in his database. This causes monotone to reject netsync operations between Jim and Beth; it doesn't matter if Beth loses Jim's email. When she tries to synchronize with him, she receives an error message indicating that the epoch does not match. She must then discuss the matter with Jim and settle on a new course of action — probably pulling Jim's database into a fresh database on Beth's end – before future synchronizations will succeed.
The previous section described the theory and rationale behind rebuilds and epochs. Here we discuss the practical consequences of that discussion.
If you decide you must rebuild your ancestry graph — generally by announcement of a bug from the monotone developers — the first thing to do is get everyone to sync their changes with the central server; if people have unshared changes when the database is rebuilt, they will have trouble sharing them afterwards.
Next, the project should pick a designated person to take down the netsync server, rebuild their database, and put the server back up with the rebuilt ancestry in it. Everybody else should then pull this history into a fresh database, check out again from this database, and continue working as normal.
In complicated situations, where people have private branches, or
ancestries cross organizational boundaries, matters are more complex.
The basic approach is to do a local rebuild, then after carefully
examining the new revision IDs to convince yourself that the rebuilt
graph is the same as the upstream subgraph, use the special db
epoch commands to force your local epochs to match the upstream ones.
(You may also want to do some fiddling with certs, to avoid getting
duplicate copies of all of them; if this situation ever arises in real
life we'll figure out how exactly that should work.) Be very careful
when doing this; you're explicitly telling monotone to let you shoot
yourself in the foot, and it will let you.
Fortunately, this process should be extremely rare; with luck, it will never happen at all. But this way we're prepared.
monotone − distributed version control system
monotone [options] <command> [parameters]
Options, which affect global behavior or set default values, come first in the argument list. A single command must follow, indicating the operation to perform, followed by parameters which vary depending on the command.
This man page is a summary of some of the features and commands of monotone, but it is not the most detailed source of information available. For a complete discussion of the concepts and a tutorial on its use, please refer to the texinfo manual (via the info monotone command, or online).
Monotone is a version control system, which allows you to keep old versions of files, as well as special revisions and manifests which describe the edit history, location, and content of files in a tree. Unlike other systems, versions in monotone are identified by cryptographic hash, and operations are authenticated by individual users' evaluating cryptographic signatures on meta-data, rather than any central authority.
Monotone keeps a collection of versions in a single-file relational database. It is essentially serverless, using network servers only as untrusted communication facilities. A monotone database is a regular file, which contains all the information needed to extract previous versions of files, verify signatures, merge and modify versions, and communicate with network servers.
[dot|count]Command line options override environment variables and settings in Lua scripts (such as .monotonerc)
info monotone
see http://savannah.nongnu.org/bugs/?group=monotone
graydon hoare <[email protected]>
accept_testresult_change (old_results, new_results): Hook Referenceattr_functions [attribute] (filename, value): Hook Referenceedit_comment (commentary, user_log_message): Hook Referenceexpand_selector (str): Hook Referenceget_author (branchname): Hook Referenceget_branch_key (branchname): Hook Referenceget_charset_conv (filename): Hook Referenceget_linesep_conv (filename): Hook Referenceget_netsync_anonymous_read_permitted (collection): Hook Referenceget_netsync_read_permitted (collection, identity): Hook Referenceget_netsync_write_permitted (collection, identity): Hook Referenceget_passphrase (keypair_id): Hook Referenceget_revision_cert_trust (signers, id, name, val): Hook Referenceget_system_linesep (): Hook Referenceignore_branch (branchname): Hook Referenceignore_file (filename): Hook Referencemerge2 (left, right): Hook Referencemerge3 (ancestor, left, right): Hook Referencemonotone --branch=branchname checkout directory: Treemonotone --branch=branchname co directory: Treemonotone add pathname...: Working Copymonotone approve id: Certificatemonotone automate ancestry_difference new [old1 [old2 [...]]]: Automationmonotone automate descendents rev1 [rev2 [...]]: Automationmonotone automate erase_ancestors [rev1 [rev2 [...]]]: Automationmonotone automate heads branch: Automationmonotone automate interface_version: Automationmonotone automate leaves: Automationmonotone automate toposort [rev1 [rev2 [...]]]: Automationmonotone cat file id: Treemonotone cat file rid path: Treemonotone cat manifest: Treemonotone cat manifest id: Treemonotone cat revision: Treemonotone cat revision id: Treemonotone cert id certname: Key and Certmonotone cert id certname certval: Key and Certmonotone certs id: Packet I/Omonotone checkout id directory: Treemonotone chkeypass id: Key and Certmonotone co id directory: Treemonotone comment id: Certificatemonotone comment id comment: Certificatemonotone commit: Working Copymonotone commit --message=logmsg: Working Copymonotone commit --message=logmsg pathname...: Working Copymonotone commit pathname...: Working Copymonotone complete file partial-id: Informativemonotone complete manifest partial-id: Informativemonotone complete revision partial-id: Informativemonotone cvs_import pathname...: RCSmonotone db check --db=dbfile: Databasemonotone db dump --db=dbfile: Databasemonotone db execute sql-statement: Databasemonotone db info --db=dbfile: Databasemonotone db init --db=dbfile: Databasemonotone db load --db=dbfile: Databasemonotone db migrate --db=dbfile: Databasemonotone db rebuild --db=dbfile: Databasemonotone db version --db=dbfile: Databasemonotone diff: Informativemonotone diff --revision=id: Informativemonotone diff --revision=id pathname...: Informativemonotone diff --revision=id1 --revision=id2: Informativemonotone diff pathname...: Informativemonotone disapprove id: Treemonotone drop pathname...: Working Copymonotone dropkey keyid: Key and Certmonotone explicit_merge id id ancestor destbranch: Treemonotone explicit_merge id id destbranch: Treemonotone fdata id: Packet I/Omonotone fdelta id1 id2: Packet I/Omonotone genkey keyid: Key and Certmonotone heads --branch=branchname: Treemonotone list branches: Informativemonotone list certs id: Informativemonotone list ignored: Informativemonotone list ignored pathname...: Informativemonotone list keys: Informativemonotone list keys pattern: Informativemonotone list known: Informativemonotone list known pathname...: Informativemonotone list missing: Informativemonotone list missing pathname...: Informativemonotone list tags: Informativemonotone list unknown: Informativemonotone list unknown pathname...: Informativemonotone list vars: Informativemonotone list vars domain: Informativemonotone log: Informativemonotone log --depth=n: Informativemonotone log --depth=n id: Informativemonotone log --depth=n id file: Informativemonotone log id: Informativemonotone log id file: Informativemonotone mdata id: Packet I/Omonotone mdelta id1 id2: Packet I/Omonotone merge --branch=branchname: Treemonotone privkey keyid: Packet I/Omonotone propagate sourcebranch destbranch: Treemonotone pubkey keyid: Packet I/Omonotone pull [address [collection]]: Networkmonotone push [address [collection]]: Networkmonotone rcs_import filename...: RCSmonotone rdata id: Packet I/Omonotone read: Packet I/Omonotone rename src dst: Working Copymonotone revert: Working Copymonotone revert pathname...: Working Copymonotone serve address collection: Networkmonotone set domain name value: Databasemonotone status: Informativemonotone status pathname...: Informativemonotone sync [address [collection]]: Networkmonotone tag id tagname: Certificatemonotone testresult id 0: Certificatemonotone testresult id 1: Certificatemonotone trusted id certname certval signers: Key and Certmonotone unset domain name: Databasemonotone update: Working Copymonotone update revision: Working Copynon_blocking_rng_ok (): Hook Referencenote_commit (new_id, certs): Hook Referencepersist_phrase_ok (): Hook Reference[1] We say sha1 values are “unique” here, when in fact there is a small probability of two different versions having the same sha1 value. This probability is very small, so we discount it.
[2] Regardless of who originally signed the certs, after the rebuild they will be signed by you. This means you should be somewhat careful when rebuilding, but it is unavoidable — if you could sign with other people's keys, that would be a rather serious security problem!